So far we have taken for granted that the data we required to carry out our analysis was available to us in a single, convenient format (e.g. csv,xls). This is usually not the case, data sources are scattered around the organization or the internet and require prior integration before any analysis or AI training can take place.
Some not so good news is that you will be spending a significant amount of your time as a data scientist, or ML engineer for that matter, chasing data and have it patched together before any meaningful analysis or AI training can take place. The good news is that Pandas offers several methods that allow you to manipulate and combine external datasets into ready for productions Pandas DataFrames.
In previous chapters we have practiced the processing and manipulation of individual DataFrames, in this chapter we will broaden our expertise by learning how to combine different datasets into a single DataFrame which is ready for further processing or analysis.
10.1 Concat Operations
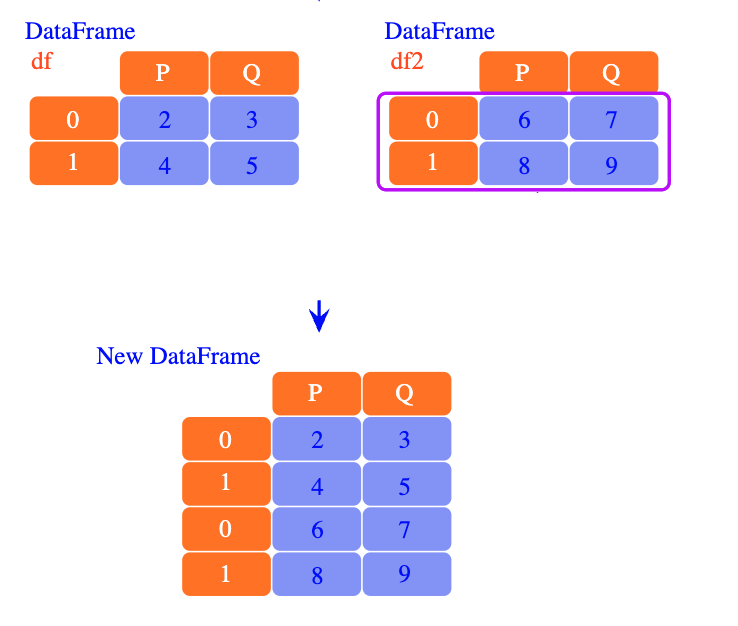
In the case of DataFrames which are similar in the sense of having the same column structure, you can use the Pandas.concat() method to combine several DataFrames into one. The Pandas.concat() operation in pandas is used to stitch together or stack multiple dataframes along a particular axis (either rows or columns), refer to the following figure:
Pandas concat operations
Example
Say we have two DataFrames, df1 and df2 and we need to concatenate both, one after the other, into a single DataFrame. We use the method Pandas.concat() as follows:
In the previous example you might have noticed that in singledataframe the index of the DataFrame is not unique (e.g. Bob and Mahmoud have the same index number ‘1’). If you need to generate a new index that is unique for each row you can specify the argument ignore_index=True as follows:
Feel free to click on the following Jupyter Notebook to run the code on Googe Colab.
10.2 Merge Operations
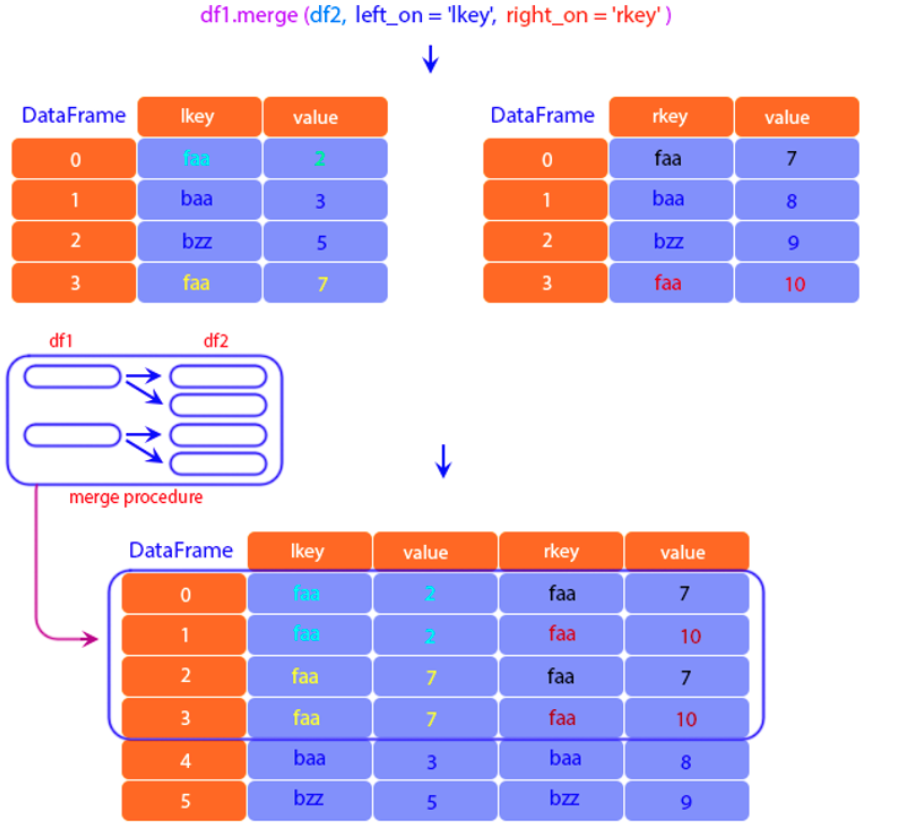
Pandas concat operations are useful when we need to integrate DataFrames with similar structures (e.g. similar columns). Combining DaFrames which are not similar, in the sense of not having the same column structure, can be performed using the Pandas.merge() method. This method allows you to combine Pandas DataFrames based on a common key (e.g. customer ID), refer to the following figure.
Pandas Merge Operation
Example
Say we have two DataFrames, df1 and df2 and we need to combine both into a single DataFrame result based on a common key Name. We use the method Pandas.concat() as follows:
In the previous example you might have noticed that only those observations having the same key Name were merged into the result DataFrame. This type of merging is called ‘inner’ and it is useful when you nee to keep only the rows where keys from both DataFrames match, the syntax is:
Merge Type
Description
Example Syntax
Inner Join
Keeps only the rows where keys from both dataframes match
pd.merge(df1, df2, on='key', how='inner')
Example
Say we have two DataFrames left and right each containing information from our company employees. We want to combine both DataFrames into a single one name result. We use the EmployeeID as the key which to merge on.
result = pd.merge(left, right, on="EmployeeID",how='inner') result
EmployeeID
Name
Unit
Salary
Bonus
0
K0
Anne
Marketing
52000
5500
1
K1
Bob
Sales
75200
32600
2
K2
Lola
Engineering
150000
25000
3
K3
Martin
Finance
25000
15000
Where is Zoe?
Notice that in the previous example the employee named ‘Zoe’ is missing from the resulting DataFrame. This is the case as her key ‘K4’ is missing in the second DataFrame and inner operations keep only the rows where keys from both dataframes match
10.2.2 Outer Merge operations
Sometimes you need to merge two DataFrames keeping all rows from both and filling in NaN (Not a Number) where there’s no match. This type of merging is called ‘outer’ and the syntax is:
Merge Type
Description
Example Syntax
Outer Join
Keeps all rows from both dataframes, filling in NaN where there’s no match
pd.merge(df1, df2, on='key', how='outer')
Example
Continuing with the previous example in this case we want to keep all employees in the resulting DataFrame result making sure that missing information is flagged as NaN
result = pd.merge(left, right, on="EmployeeID",how='outer') result
EmployeeID
Name
Unit
Salary
Bonus
0
K0
Anne
Marketing
52000.0
5500
1
K1
Bob
Sales
75200.0
32600
2
K2
Lola
Engineering
150000.0
25000
3
K3
Martin
Finance
25000.0
15000
4
K4
Zoe
Human Resources
NaN
NaN
Zoe is back
Notice that this time the employee named ‘Zoe’ shows up in the resulting DataFrame yet there is no information on her salary and bonus. This is the case as in the second DataFrame right there isn’t any entry for Zoe’s key K4.
10.2.3 Left Merge operations
Sometimes you need to merge two DataFrames keeping all rows from the left DataFrame both and filling in NaN where there’s no match. This type of merging is called ‘left’ and the syntax is:
Merge Type
Description
Example Syntax
Left Join
Keeps all rows from the left dataframe and matches from the right dataframe
pd.merge(df1, df2, on='key', how='left')
Example
Continuing with the previous example in this case we want to keep all rows from the left DataFrame.
in the resulting DataFrame result making sure that missing information is flagged as NaN
result = pd.merge(left, right, on="EmployeeID",how='left') result
EmployeeID
Name
Unit
Salary
Bonus
0
K0
Anne
Marketing
52000.0
5500
1
K1
Bob
Sales
75200.0
32600
2
K2
Lola
Engineering
150000.0
25000
3
K3
Martin
Finance
25000.0
15000
4
K4
Zoe
Human Resources
NaN
NaN
10.2.4 Right Merge operations
Sometimes you need to merge two DataFrames keeping all rows from the right DataFrame both and filling in NaN where there’s no match. This type of merging is called ‘right’ and the syntax is:
Merge Type
Description
Example Syntax
Right Join
Keeps all rows from the right dataframe and matches from the left dataframe
pd.merge(df1, df2, on='key', how='right')
Example
Continuing with the previous example in this case we want to keep all rows from the right DataFrame.
in the resulting DataFrame result making sure that missing information is flagged as NaN
result = pd.merge(left, right, on="EmployeeID",how='right') result
EmployeeID
Name
Unit
Salary
Bonus
0
K0
Anne
Marketing
52000
5500
1
K1
Bob
Sales
75200
32600
2
K2
Lola
Engineering
150000
25000
3
K3
Martin
Finance
25000
15000
Where is Zoe?
Notice that in the previous example the employee named ‘Zoe’ is missing from the resulting DataFrame. This is the case as her key ‘K4’ is missing in the second DataFrame and right operations keep only rows from the right DataFrame
10.3 Join Operations
An alternative approach to combine Pandas DataFrames based on a common key is ‘DataFrame.join()’. It is quite similar to Pandas.merge().
Example
Given our previous dataframes, left and right and we need to combine both into a single DataFrame result based on a common key Name. We use the method DataFrame.join() as follows:
result = left.merge( right, on='EmployeeID',how='inner')result
EmployeeID
Name
Unit
Salary
Bonus
0
K0
Anne
Marketing
52000
5500
1
K1
Bob
Sales
75200
32600
2
K2
Lola
Engineering
150000
25000
3
K3
Martin
Finance
25000
15000
The following code illustrates a join operation over the same pair of DataFrames
result = left.merge( right, on='EmployeeID',how='outer')result
EmployeeID
Name
Unit
Salary
Bonus
0
K0
Anne
Marketing
52000.0
5500
1
K1
Bob
Sales
75200.0
32600
2
K2
Lola
Engineering
150000.0
25000
3
K3
Martin
Finance
25000.0
15000
4
K4
Zoe
Human Resources
NaN
NaN
10.4 Data Joining in Practice
TODO include tip boxes suggesting the use of gemini to address software challenges
First Example
Let’s have a look at the following Jupyter Notebook. This notebook accesses, via API, external datasets relative to the quality of air in cities across the world, then concatenates different datasets and conducts a basic benchmark of air quality of different cities.
Second Example
Let’s have a look at the following Jupyter Notebook. This notebook continues with the analysis of air quality this time performing more advanced transformation on the datasets.
Using Generative AI for coding purposes
Don’t forget to ask Gemini in case you need some help on DataFrame transformations or visualizations
Third Example (Retail Lab)
Let’s have a look at the following Jupyter Notebook. This notebook illustrates the processing of a series of retail related datasets.
10.5 Conclusion
The methods Pandas.concat(), Pandas.merge() and DataFrame.join() are important in any data science or ML related project as they allow you to combine real world, heterogeneous, datasets. Newcomers to data transformation tend to be confused as to which method to use to combine DataFrames:
Pandas.concat() applies when you just want to glue together DataFrames vertically (stacking rows) or horizontally (stacking columns). Think of it as just putting pieces next to each other.
Pandas.merge(), a bit more advanced, merge() is like SQL joins. It allows you to combine two DataFrames based on a common column(s). This is your go-to for combining data where there’s a common link but potentially with complex relationships.
DataFrame.join() is similar to merge(), but it is more for combining DataFrames based on their indices instead of columns. It’s super useful when your data is already aligned by index.
The following table provides a summary of the different types of merge operations
Merge Type
Description
Example Syntax
Inner Join
Keeps only the rows where keys from both dataframes match
pd.merge(df1, df2, on='key', how='inner')
Outer Join
Keeps all rows from both dataframes, filling in NaN where there’s no match
pd.merge(df1, df2, on='key', how='outer')
Left Join
Keeps all rows from the left dataframe and matches from the right dataframe
pd.merge(df1, df2, on='key', how='left')
Right Join
Keeps all rows from the right dataframe and matches from the left dataframe