2 Introduction to Jupyter Notebooks
Jupyter Notebooks are open-source web applications that allow users to create and share documents containing live code, equations, visualizations, and narrative text. They support multiple programming languages, although Python, R, and Julia are the most commonly used in data science contexts. Jupyter Notebooks are relevant in data science as they facilitate:
Exploratory Data Analysis (EDA): Jupyter Notebooks allow data scientists to perform EDA interactively. This phase often requires a lot of experimentation and visualization, making the step-by-step execution of code in a notebook particularly valuable.
Prototyping and Iteration: The ability to quickly test hypotheses and algorithms in a notebook fosters rapid prototyping, which is important in data science where results can be unpredictable.
Collaboration and Communication: Jupyter Notebooks facilitate collaboration among teams. Users can add explanations alongside code, making it easier for team members to understand the analysis and results. It’s also a great tool for sharing insights with non-technical stakeholders.
Documentation and Reporting: The mixture of executable code and narrative text enables data scientists to create comprehensive reports that can serve both as documentation and as educational resources.
Integration with Data Sources: Jupyter can easily connect to various data sources (like databases, APIs, or CSV files), allowing for seamless data retrieval and manipulation.
Education and Training: Jupyter is widely used in academic settings for teaching data science and programming because it allows for practical, hands-on learning.
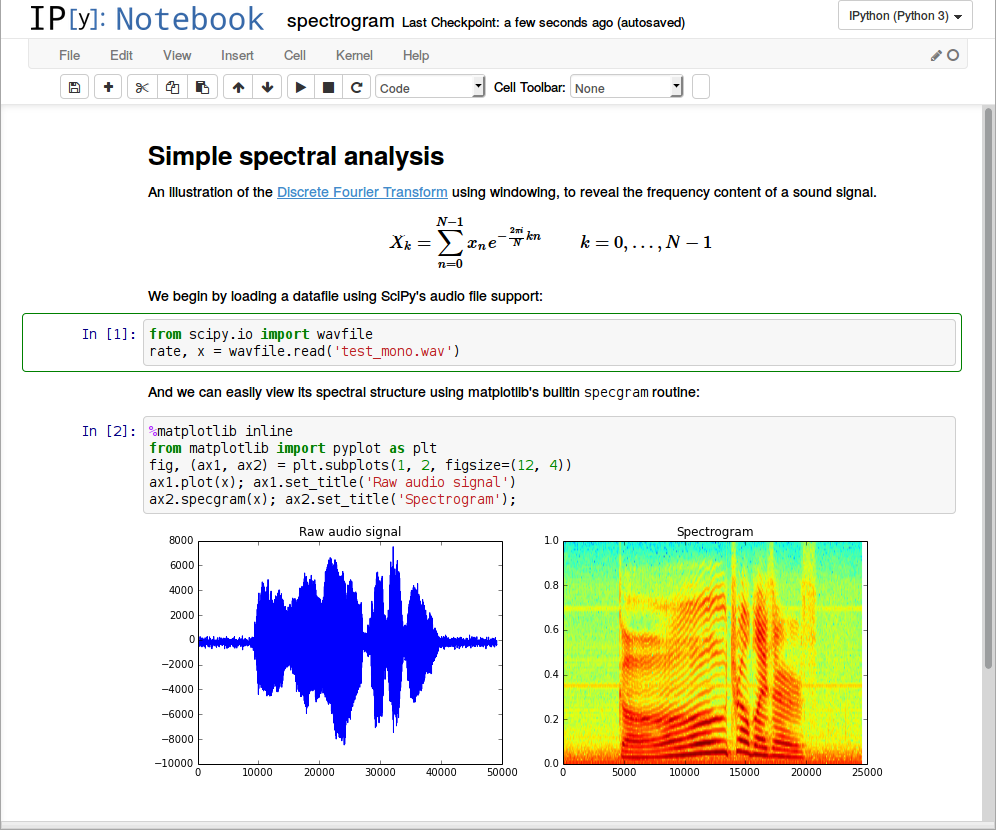
The following figure shows a snapshot of a Jupyter Notebook containing textual information, software code and some visualizations. This Jupyter Notebook illustrates how to perform a complex mathematical operation over a sound signal and visualize the result of this mathematical operation.
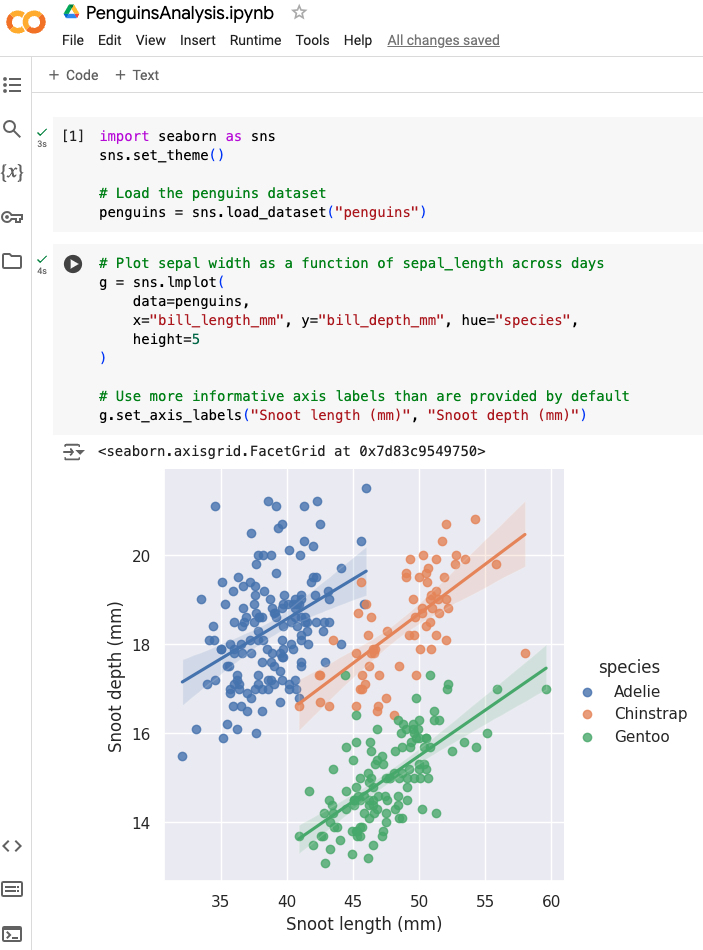
The following figure shows a snapshot of a Jupyter Notebook in which we conduct a basic statistical analysis of the well known penguins dataset. Don’t worry if you don’t understand what is going on in the notebook, this book is aimed precisely at making you capable of understanding existing notebooks and developing new ones.
2.1 My first Jupyter Notebook
Let’s work on our very first Jupyter Notebook. We will rely on Google Colab, a free service provided by Google that allows us to develop and run Notebooks in the cloud. Don’t worry about being locked into Google’s technologies, Jupyter Notebooks can be hosted and executed in other vendor’s platforms (e.g. Amazon AWS, Microsoft Azure).
Please feel free to click on My First Jupyter Notebook to fire up Google Colab and get access to the notebook, you might need to sign up using a google gmail account.
The Jupyter Notebook interface typically consists of a toolbar and a cell area.
- Toolbar: Provides quick access to many functions, such as saving the notebook, running cells, adding new cells, and more.
- Cell Area: The main area where users write code and text.
Jupyter Notebooks have a well-defined structure that organizes content into cells. Cells are the core building blocks of a Jupyter Notebook. There are two primary types of cells:
Code Cells: These cells contain executable code snippets. When run, the code executes and can produce output that appears directly below the cell.
Markdown Cells: These cells can contain formatted text, including headers, lists, links, images, and mathematical equations using LaTeX. Markdown allows users to add notes and explanations to the notebook, enhancing readability.
When a code cell is executed, any output generated by that code (such as print statements, visualizations, tables, or error messages) is displayed just beneath the cell. This immediate feedback loop supports interactive exploration.
To run code cells on Google Colab just click on the play button before the code
Each cell can be executed independently, and Google Colab keeps track of the execution order. This means that outputs can depend on previously run cells, making it easy to update results by rerunning specific parts of the notebook without restarting the entire analysis.
2.2 Conclusion
Jupyter Notebooks are versatile applications that allow the ingestion, transformation, processing, analysis and visualization of data. Data Architects develop notebooks to ingest and transform data sources to have them ready for further consumption down the data science cycle. Data Scientists develop notebooks to carry out exploratory data analysis (EDA), advanced statistical analysis and subsequent reports. AI Engineers develop notebooks to ingest datasets and train their own AI-based inference systems.
In this sense Jupyter Notebooks are critical pillars in any data science workflow and any aspiring scientist or AI engineer is expected to be proficient at developing and running Notebooks.
2.3 Further Readings
At this point in your learning journey that is all you need to start working with Jupyter Notebooks. However if you want to learn more about them please refer to the following references for additional readings.
Jupyter Notebook Documentation
Examples of Jupyter Notebooks hosted on Google Colab