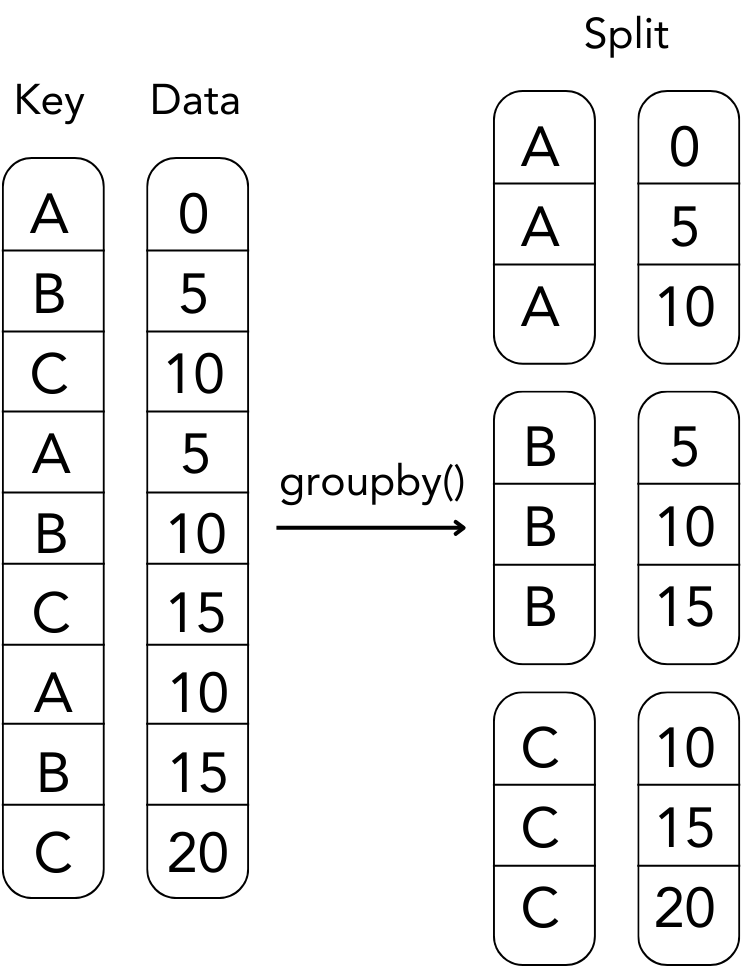
In Chapter 6 you practiced basic grouping operations over pandas DataFrames. The Pandas DataFrame.groupby() method split the original DataFrame based on a given key into several groups, refer to the following figure.
Grouping Operation
The following example applies a groupby() operation to a DataFrame df using the column Division as the grouping key. Notice that it returns a DataFrameGroupBy.
import pandas as pddata = {'EmployeeID': ['F0099','F1010','M2020','M2021','E0100','E1000','E3434'],'Name': ['Alice', 'Bob', 'Charlie','John','Sean','Tobias','Francois'], # Column 'Name' with names'Age': [25, 30, 35,50,47,59,55], # Column 'Age' with ages'Division': ['Finance','Finance','Marketing','Marketing','Engineering','Engineering','Engineering'],'City': ['New York', 'Los Angeles', 'Beijing','Hong Kong','London','Beijing','London'], # Column 'City' with cities'Salary': [70000, 80000, 60000,45000,125000,36000,250000],# Column 'Salary' with salaries'Bonus': [1000,1500,30000,23000,20000,25000,15000]}# Step 3: Create the DataFramedf = pd.DataFrame(data)df.set_index('EmployeeID',inplace=True)# Display the DataFramedf
Name
Age
Division
City
Salary
Bonus
EmployeeID
F0099
Alice
25
Finance
New York
70000
1000
F1010
Bob
30
Finance
Los Angeles
80000
1500
M2020
Charlie
35
Marketing
Beijing
60000
30000
M2021
John
50
Marketing
Hong Kong
45000
23000
E0100
Sean
47
Engineering
London
125000
20000
E1000
Tobias
59
Engineering
Beijing
36000
25000
E3434
Francois
55
Engineering
London
250000
15000
# grouping by DivisiondfGroupedByDivision=df.groupby('Division')dfGroupedByDivision
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x1051ed670>
DataFrameGroupBy objects
the previous groupby() operation returned a DataFrameGroupBy object which, as you will see next can be iterated over using for loops.
Iterating over Groups
It is possible to implement fine-grained processing of groups by iterating over them using ‘for’ loops. The following example iterates over dfGroupedByDivision, in this case just printing each group’s rows.
for division,group in dfGroupedByDivision:print('I have found:',division)print(group)
I have found: Engineering
Name Age Division City Salary Bonus
EmployeeID
E0100 Sean 47 Engineering London 125000 20000
E1000 Tobias 59 Engineering Beijing 36000 25000
E3434 Francois 55 Engineering London 250000 15000
I have found: Finance
Name Age Division City Salary Bonus
EmployeeID
F0099 Alice 25 Finance New York 70000 1000
F1010 Bob 30 Finance Los Angeles 80000 1500
I have found: Marketing
Name Age Division City Salary Bonus
EmployeeID
M2020 Charlie 35 Marketing Beijing 60000 30000
M2021 John 50 Marketing Hong Kong 45000 23000
Iterating over DataFrameGroupBy objects
Iterating over a DataFrameGroupBy object is not as complicated at it seems, just bear in mind that you are looping over a series of groups and that each group is a yet another Pandas DataFrame.
As in any other regular for loop you can implement conditional filtering to process only specific groups. The following example iterates over dfGroupedByDivision, in this case it prints each group’s rows and finds the top earner. Given the if clause inside the loop only the Engineering division is processed.
for division,group in dfGroupedByDivision:print('I have found:',division)if division=='Engineering':print('I am processing:',division)print(group) topEarner=group['Salary'].max()print("The higest salary in the group is:",topEarner)print("\n")
I have found: Engineering
I am processing: Engineering
Name Age Division City Salary Bonus
EmployeeID
E0100 Sean 47 Engineering London 125000 20000
E1000 Tobias 59 Engineering Beijing 36000 25000
E3434 Francois 55 Engineering London 250000 15000
The higest salary in the group is: 250000
I have found: Finance
I have found: Marketing
Caution when iterating over DataFrameGroupBy objects
We advise caution when deciding to iterate over a DataFrameGroupBy object as it usually degrades performance and memory bottlenecks when dealing with large datasets. We recommend, whenever possible, to rely on aggregation, transformation and filtration operations. We will review these operations in subsequent sections of this chapter.
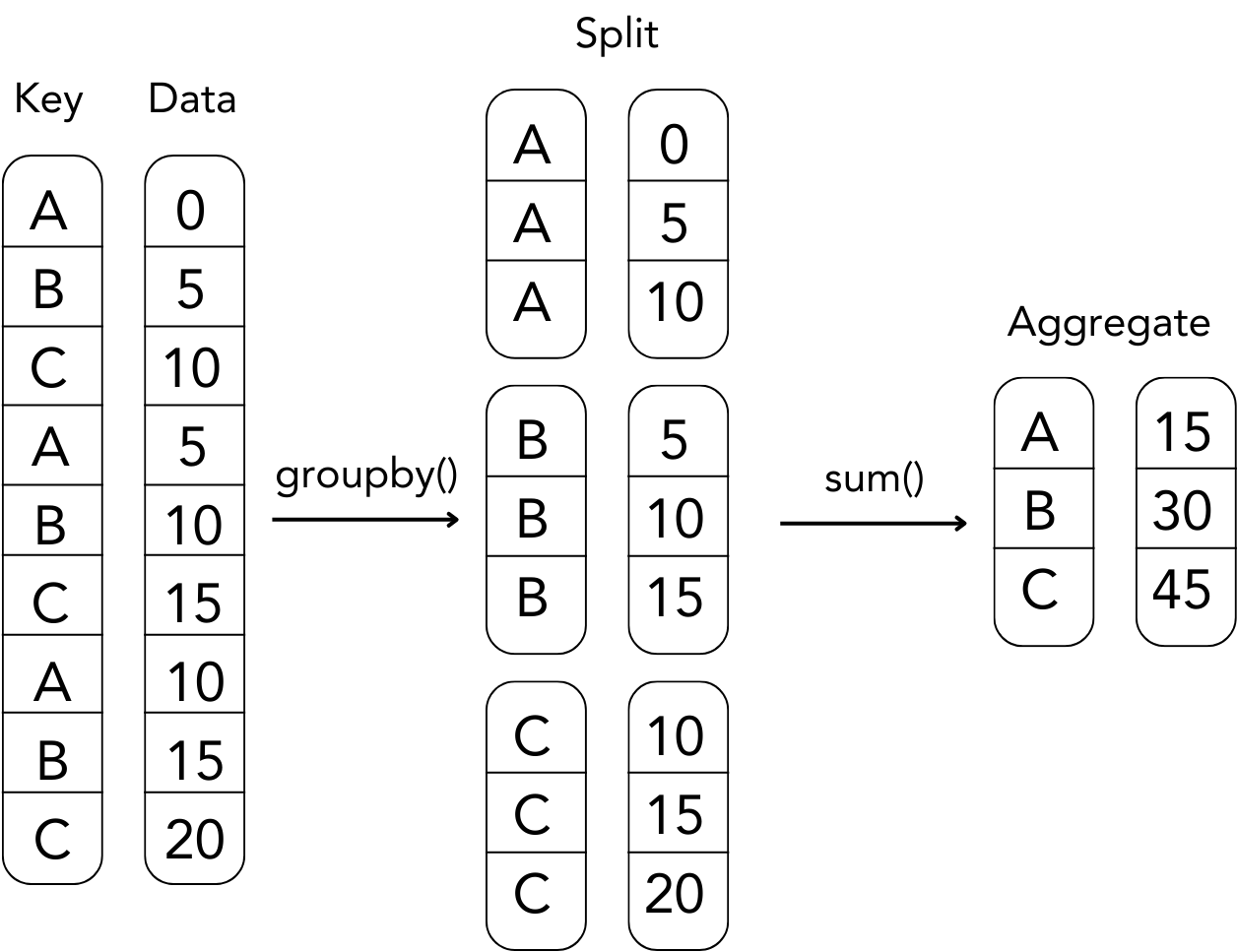
14.2 Grouping-Aggregation Operations
In Chapter 6 you practiced basic aggregation and grouping of pandas DataFrames. A grouping-aggregation operation takes a DataFrameGroupBy object and applies a method, or your own function, to each group, refer to the following figure. Advanced grouping-aggregation operations are implemented combining the DataFrame.groupby() with the DataFrameGroupBy.agg() method.
Grouping-Aggregation Operation
Single column grouping, single column aggregation
You know already how to to perform grouping operations on a single column and subsequent aggregation of another column. For instance the following example: (1) groups the dataframe df on the column Division, (2) aggregates the Salary column using the sum() method.
df.groupby('Division').agg({'Salary':'sum'})
Salary
Division
Engineering
411000
Finance
150000
Marketing
105000
Multiple column grouping, single column aggregation
Grouping by several columns is quite a common requirement in data science. The following example (1) groups the dataframe df on the column Division and City, (2) aggregates the Salary column using the sum() method.
Indeed it is possible to perform grouping operations over several columns and aggregation over other columns. The following example (1) groups the dataframe df on the column Division and City, (2) aggregates both Salary and Bonus columns using the DataFrameGroupBy.sum() method.
Oftentimes you will need to determine the type of object being created after an operation in Python, for this the method type() is useful, for instance for the previous example:
The DataFrameGroupBy.agg() method allows aggregation operations based on built-in methods as well as your own defined functions. For instance the following example: (1) groups the dataframe df on the column Division, (2) aggregates the Salary column using the DataFrameGroupBy.sum() method, (3) aggregates the Bonus column using the DataFrameGroupBy.mean() method.
The following code illustrates a combined grouping and aggregation operation based on the built-in method DataFrameGroupBy.mean() and a regular function called custom_func()
Refer to the following table for a list of built-in DataFrameGroupBy methods available to perform aggregation operations.
Method
Description
any()
Compute whether any of the values in the groups are truthy
all()
Compute whether all of the values in the groups are truthy
count()
Compute the number of non-NA values in the groups
cov()
Compute the covariance of the groups
first()
Compute the first occurring value in each group
idxmax()
Compute the index of the maximum value in each group
idxmin()
Compute the index of the minimum value in each group
last()
Compute the last occurring value in each group
max()
Compute the maximum value in each group
mean()
Compute the mean of each group
median()
Compute the median of each group
min()
Compute the minimum value in each group
nunique()
Compute the number of unique values in each group
prod()
Compute the product of the values in each group
quantile()
Compute a given quantile of the values in each group
sem()
Compute the standard error of the mean of the values in each group
size()
Compute the number of values in each group
skew()
Compute the skew of the values in each group
std()
Compute the standard deviation of the values in each group
sum()
Compute the sum of the values in each group
var()
Compute the variance of the values in each group
14.3 Grouping-Transformation Operations
Transformation operations in Pandas are useful when you want to perform some computation on groups and return an object that is the same size as the original DataFrame. This is different from grouping-aggregation operations that, usually, produces a single value per group (e.g. the mean ). Transformation operations are useful for statistical normalization, group-based feature engineering, and custom transformations.
Grouping-transformation operations are implemented combining the DataFrame.groupby() with the DataFrameGroupBy.transform() method.
Grouping-Transformation Operation
The following code illustrates a combined grouping and transformation operation based on the built-in method DataFrameGroupBy.cumsum(). It groups the dataframe df on the column Division, (2) computes the cumulative sum of the Age column within each group.
The previous example illustrates a quite common use case in practice: ordering within groups for instance for instance to rank customers based on their purchases or to rank commercial branches based on their sales performance.
A specially interesting use case in which transformations are indicated is the so called Z-Score Normalization whereby we need to compute the Z-score for each value within its group. A Z-score represents the number of standard deviations a data point is from the mean of its group. For this, you can use transform with a lambda function.
# Compute the Z-score within each groupdf['Salary_Zscored'] = df.groupby('Division')['Salary'].transform(lambda x: (x - x.mean()) / x.std())df
Name
Age
Division
City
Salary
Bonus
Age_Rank
Salary_Zscored
EmployeeID
F0099
Alice
25
Finance
New York
70000
1000
1.0
-0.707107
F1010
Bob
30
Finance
Los Angeles
80000
1500
2.0
0.707107
M2020
Charlie
35
Marketing
Beijing
60000
30000
1.0
0.707107
M2021
John
50
Marketing
Hong Kong
45000
23000
2.0
-0.707107
E0100
Sean
47
Engineering
London
125000
20000
1.0
-0.111624
E1000
Tobias
59
Engineering
Beijing
36000
25000
3.0
-0.939504
E3434
Francois
55
Engineering
London
250000
15000
2.0
1.051129
Refer to the following table for a list of built-in DataFrameGroupBy methods available to perform transformation operations.
Method
Description
bfill()
Back fill NA values within each group
cumcount()
Compute the cumulative count within each group
cummax()
Compute the cumulative max within each group
cummin()
Compute the cumulative min within each group
cumprod()
Compute the cumulative product within each group
cumsum()
Compute the cumulative sum within each group
diff()
Compute the difference between adjacent values within each group
ffill()
Forward fill NA values within each group
pct_change()
Compute the percent change between adjacent values within each group
rank()
Compute the rank of each value within each group
shift()
Shift values up or down within each group
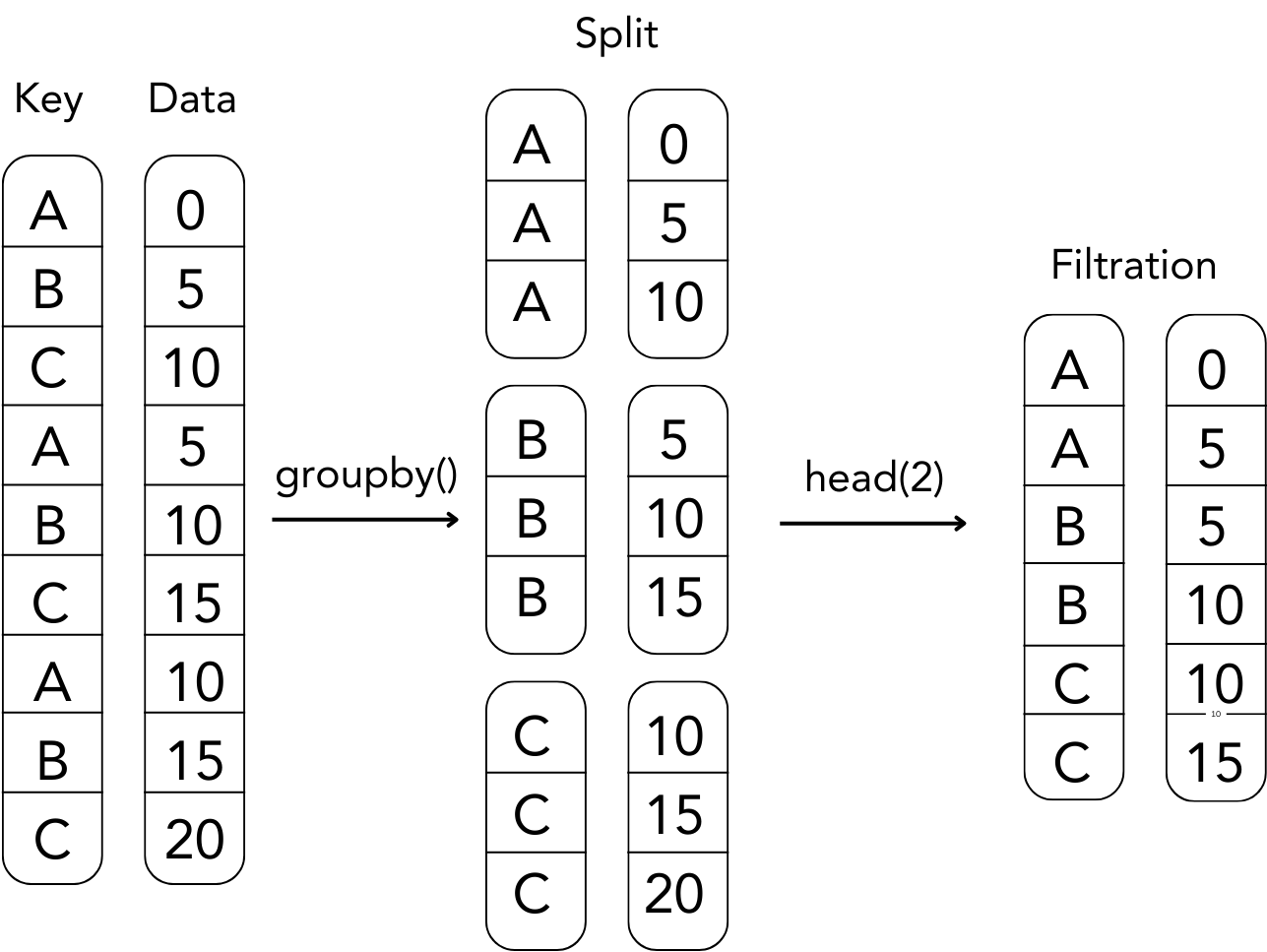
14.4 Grouping-Filtration Operations
Filtration in Pandas allows you to filter out entire groups based on a condition. This is particularly useful when you’re working with grouped data and you want to exclude some groups based on aggregate statistics or other criteria. Refer to the following figure.
Grouping-Filtration Operation
The following example groups the dataframe df on the column Division, (2) filters the first row of each group
df.groupby('Division').head(1)
Name
Age
Division
City
Salary
Bonus
Age_Rank
Salary_Zscored
EmployeeID
F0099
Alice
25
Finance
New York
70000
1000
1.0
-0.707107
M2020
Charlie
35
Marketing
Beijing
60000
30000
1.0
0.707107
E0100
Sean
47
Engineering
London
125000
20000
1.0
-0.111624
The following example groups the dataframe df on the column Division, (2) extracts only groups in which the salary mean is larger than 70000.
Following please find some examples of python code. Try to understand what the code is trying to accomplish before checking the solution below:
Example: Would you survive the Titanic disaster?
import pandas as pd# URL of the Titanic dataseturl ='https://raw.githubusercontent.com/thousandoaks/Python4DS-I/refs/heads/main/datasets/Titanic-Dataset.csv'# Load the dataset into a DataFramedf = pd.read_csv(url)grouped_data = df.groupby(['Pclass', 'Sex'])['Survived'].mean()# Display the grouped datadisplay(grouped_data)
Explanation:
The groupby() function groups the dataset by the Pclass (passenger class) and Age columns. The mean() function aggregates the number of occurrences in the Survived column.
Pclass Sex
1 female 0.968085
male 0.368852
2 female 0.921053
male 0.157407
3 female 0.500000
male 0.135447
Name: Survived, dtype: float64
Example: Have you been overcharged for your Titanic voyage?
import pandas as pd# URL of the Titanic dataseturl ='https://raw.githubusercontent.com/thousandoaks/Python4DS-I/refs/heads/main/datasets/Titanic-Dataset.csv'# Load the dataset into a DataFramedf = pd.read_csv(url)# Group by 'Pclass' and compute the Z-score of 'Fare'df['Fare_Zscore'] = df.groupby('Pclass')['Fare'].transform(lambda x: (x - x.mean()) / x.std())# Display the updated DataFrame with the new Z-score columndisplay(df[['Pclass', 'Fare', 'Fare_Zscore']])
Explanation:
The groupby(‘Pclass’) groups the data based on passenger class, then the operation transform() computes the Z-score of Fare within each class.
Pclass
Fare
Fare_Zscore
0
3
7.2500
-0.545549
1
1
71.2833
-0.164217
2
3
7.9250
-0.488239
3
1
53.1000
-0.396205
4
3
8.0500
-0.477626
...
...
...
...
886
2
13.0000
-0.571063
887
1
30.0000
-0.690922
888
3
23.4500
0.829880
889
1
30.0000
-0.690922
890
3
7.7500
-0.503097
891 rows × 3 columns
Example: Titanic top spenders per class
import pandas as pd# URL of the Titanic dataseturl ='https://raw.githubusercontent.com/thousandoaks/Python4DS-I/refs/heads/main/datasets/Titanic-Dataset.csv'# Load the dataset into a DataFramedf = pd.read_csv(url)top_3_fares_per_class = df.groupby('Pclass')['Fare'].nlargest(3)display(top_3_fares_per_class)
Explanation:
The code groups the Titanic dataset by Pclass, selects the top 3 highest fares within each class using nlargest(3)
Let’s have a look at the following Jupyter Notebook. This notebook illustrates the application of groupby operations to a healthcare dataset.
14.6.2 Second Example
The following Retail Example illustrates how to perform advanced data grouping and subsequent aggregations on a retail dataset
14.7 Conclusions
This chapter explores advanced grouping operations in pandas, building on the DataFrame.groupby() method to split DataFrames into groups for analysis. It introduces iterating over DataFrameGroupBy objects for fine-grained processing. Grouping-aggregation operations, implemented via agg(), allow for single or multi-column grouping with diverse aggregation methods, including built-in functions and custom or lambda functions. Grouping-transformation operations, using transform(), enable calculations such as cumulative sums, ranking within groups, and Z-score normalization, adding new columns to the original DataFrame. Lastly, grouping-filtration operations filter out entire groups based on conditions, such as excluding groups with low mean values. Practical use cases in digital marketing, healthcare, and retail highlight the real-world utility of these techniques, with links to illustrative Jupyter Notebooks.
In the next chapter you will explore how to perform advanced data retrieval from external datasources including SQL databases.
14.8 Further Readings
For those interested in additional examples and references on comprehensions feel free to check the following: