The ability to separate a DataFrame into groups based on some characteristics (e.g. customer ID) and perform some computations over each group (e.g. purchases across time) is critical in data science as it allows us to conduct group-based analyses, for instance performance benchmarking (e.g. customer churning, business units revenues). In Pandas this is accomplished with data aggregation and grouping operations.
Data aggregation is the process of summarizing a dataset, usually to compute a metric (for instance the mean of a data series) or to condense large amounts of data into a more manageable form for subsequent processing or visualization.
Data Grouping is the process of splitting a given dataset into groups based on some characteristics (e.g. regional areas, hospital name, customer ID)
It is possible to perform really complex data transformations by combining data grouping and aggregation. For example, as shown in the following figure, you might want to calculate the average sales per region from a dataset that includes tons of sales records or simply summarize information to be consumed by business managers.
Uses of Data Aggregation and Grouping
6.1 Data Aggregation
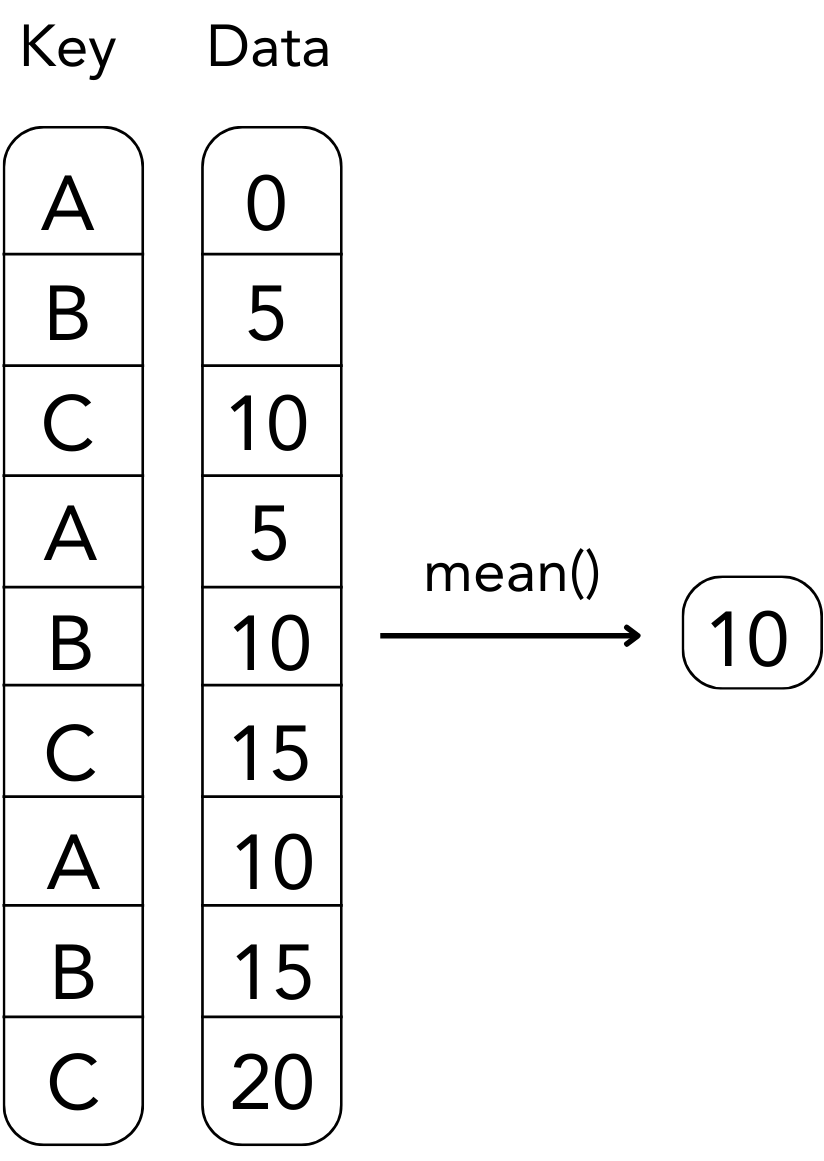
Pandas based data aggregation is performed by applying a method, for instance mean(), to a specific column of a DataFrame, refer to the following figure.
Pandas based Data Aggregation
The following example illustrates how to compute the mean of a sales data. To do so pandas applies the mean() method to the column ‘Sales’ of the dataframe corporatesales.
# Average Salesmean_sales = corporatesales['Sales'].mean()print("Average sales:\n", mean_sales)
Average sales:
233.33333333333334
Following on the previous example we can compute the minimum and maximum sales by applying the min() and max() methods to the column ‘Sales’:
# Min Salesmin_sales = corporatesales['Sales'].min()print("Minimum sales:\n", min_sales)
Minimum sales:
100
# Max Salesmax_sales = corporatesales['Sales'].max()print("Maximum sales:\n", max_sales)
Maximum sales:
400
Pandas offers convenient methods to aggregate data from a given DataFrame, refer to the following table. In future chapters you will learn how to develop and apply your own customized methods.
Function Name
Description
count
Number of non-null values
cumsum
Cumulative sum of non-null values
cumprod
Cumulative product of non-null values
first,last
First and last non-null values
mean
Mean of non-null values
median
Arithmetic median of non-null values
min,max
Minimum and maximum of non-null values
prod
Product of non-null values
size
Compute group sizes, returning result as a Series
sum
Sum of non-null values
std,var
Sample standard deviation and variance
6.2 Data Aggregation and Grouping Operations
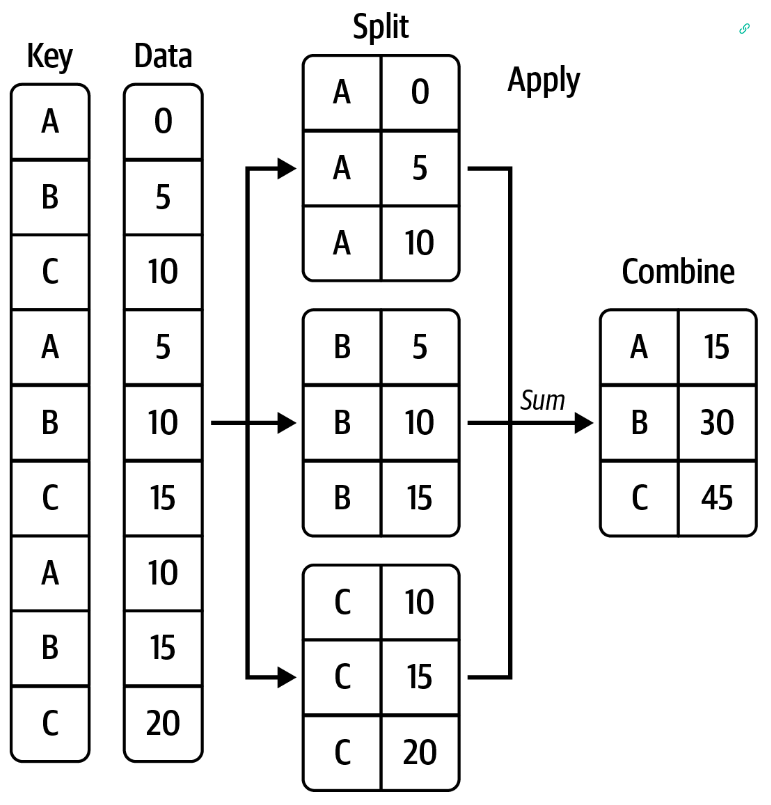
Pandas provides data aggregation and grouping capabilities by way of the groupby() method. Pandas groupby() operations follow the split-apply-combine paradigm whereby a given DataFrame is: (1) Split into groups, (2) a function is applied to each group, (3) results are combined into a new DataFrame.
Example (Addition across groups)
The following figure illustrates a data aggregation and grouping operation that:
Splits the original DataFrame df into groups based on the key ‘CustomerID’.
Applies the method sum() to each of the previous groups.
combines the result in a new DataFrame ‘total_sales’
# Group by CustomerIDgrouped = df.groupby('CustomerID')# Total Purchases per Customertotal_sales = grouped['Purchases'].sum()print("Total Sales per Customer:\n", total_sales)
Total Sales per Customer:
CustomerID
A 15
B 30
C 45
Name: Purchases, dtype: int64
It is possible to perform the same groupby operation with just one line of code as following:
# one liner groupbytotal_sales = df.groupby('CustomerID')['Purchases'].sum()print("Total Sales per Customer:\n", total_sales)
Total Sales per Customer:
CustomerID
A 15
B 30
C 45
Name: Purchases, dtype: int64
Example (Counting across groups)
The following code illustrates how to count the number of elements accross groups:
group_counts = df.groupby('CustomerID')['Purchases'].count()print("Number of elements per group:\n", group_counts)
Number of elements per group:
CustomerID
A 3
B 3
C 3
Name: Purchases, dtype: int64
Using Generative AI for coding purposes
Indeed it is possible to rely on your favorite assistant to get a starting code for any given groupby-aggregation operation. To do so you just need to submit the following prompt:
“I need python code to compute the top 3 per group in a pandas”
6.3 Code Interpretation Challenge
Following please find some examples of python code. Try to understand what the code is trying to accomplish before checking the solution below:
Example: Performing GroupBy operations on the Penguins dataset
import pandas as pd# Load the penguins dataseturl ="https://raw.githubusercontent.com/thousandoaks/Python4DS-I/refs/heads/main/datasets/penguins.csv"penguins = pd.read_csv(url)avg_body_mass_by_species = penguins.groupby('species')['body_mass_g'].mean()display(avg_body_mass_by_species)
Explanation:
This code groups the dataset by the species column and then calculates the mean of the body_mass_g column for each species. The groupby() function creates groups based on unique species, and the mean() function computes the average body mass within each group. The result is a Series object displaying the average body mass for each penguin species.
Here, the dataset is grouped by the island column, and the size() function counts the number of occurrences (rows) in each group. This operation provides the total number of penguins observed on each island. The output is a Series object with islands as the index and the corresponding counts as values.
island
Biscoe 168
Dream 124
Torgersen 52
dtype: int64
Example: Yet another Groupby operation on Penguins
This example demonstrates grouping the dataset by both species and sex columns. The groupby function creates a MultiIndex based on the unique combinations of species and gender. The mean() function then computes the average flipper_length_mm for each combination. The result is a Series object with a hierarchical index (species and sex) and the corresponding mean flipper lengths as values.
species sex
Adelie FEMALE 187.794521
MALE 192.410959
Chinstrap FEMALE 191.735294
MALE 199.911765
Gentoo FEMALE 212.706897
MALE 221.540984
Name: flipper_length_mm, dtype: float64
6.4 Data Grouping in Practice
6.4.1 First Example
Let’s have a look at the following Jupyter Notebook. This notebook processes the well-known titanic dataset and performs several groupby operations to find differences in the age and ticket price across males and females.
Challenge yourself by developing some code to determine the odds of surviving of females against males. Try to work it out on your own before checking the solution below:
Code
# We split the titanic dataset into females and males and compute the mean of the Survived column for each grouptitanic.groupby('Sex')['Survived'].mean()
6.4.2 Second Example
Let’s have a look at the following Jupyter Notebook. This notebook processes an econometric dataset and computes several economic metrics such as life expectancy, gross domestic product (GDP) across countries. This allows us to determine, for instance, which countries have the largest life expectancy and whether there is any relationship between GDP and life expectancy.
Challenge yourself by developing some code to determine the relationship between GDP and life expectancy (Tip. consider splitting into continents). Try to work it out on your own before checking the solutions below:
Code
# We split the gapminder dataset by continent then we compute the mean# for the columns lifeExp and gdpPercapgapminderDataFrame.groupby('continent')[['lifeExp','gdpPercap']].mean()
Using Generative AI for coding purposes
In the previous example try the following prompt on Google Gemini:
“How to determine the relationship between GDP and life expectancy?”
6.5 Conclusion
Data scientists must be proficient in the application of aggregation and grouping operations to process data and derive meaningful insights from it. Pandas groupby() is an extremely versatile operation capable of processing complex time series, econometric panel data and many others. We have just touched the tip of the iceberg of what it is possible to accomplish with groupby(), future chapters will illustrate more advanced uses of grouping operations. it is advised to invest a significant amount of time mastering groupby operations; they are the bread and butter of any data scientist.
In the next chapter you will learn how to filter data based on conditions, this will allow you to select based on gender or salary income for instance.
6.6 Further Readings
For those of you in need of additional, more advanced, topics please refer to the following references: