Inspired by the old adagio “a data visualization is worth a thousand numbers” visualizations are critical for the success of any data science endeavor. In my professional experience it is so very much the case that business managers do not have neither the time nor the patience to go through convoluted mathematical analyses and numerical results, therefore you as an aspiring data scientist need to be proficient at developing visual representations of your analyses.
Data visualizations are instrumental in data science as they:
Simplify Complex Data. Data can be messy and complex. Visualizations help to distill this information into something that is much easier to understand. For example, a chart or graph can show trends and patterns that might be hidden in a table full of numbers.
Spot Trends and Outliers. With visualizations, it is easier to spot trends over time or identify outliers that may require further investigation. A line graph can show you a spike in sales, while a scatter plot can quickly highlight unusual data points that do not fit the pattern.
Better Communication. When you’re sharing your findings, visuals can help convey your message more effectively. If you present data in a well-designed visualization, it engages your audience and makes your analysis more persuasive. Not everyone loves diving deep into spreadsheets, right?
Aid in Decision-Making. In business settings, stakeholders often rely on visual representations to make informed decisions. Clear visuals can help them understand risks, opportunities, and the overall performance of strategies quickly.
Encourage Exploration. Visualizations allow viewers to interact with the data, encouraging exploration. For instance, dashboards can enable users to dive deeper into specific areas of interest, leading to new insights.
Storytelling. Good visualizations tell a story. Whether you’re outlining a journey of your data, showcasing a significant change, or indicating a prediction, storytelling through visuals makes the data relatable and memorable.
Support Insights. When you wrap up an analysis, visuals can dramatically support your insights. They help to validate your claims with evidence that is easily digestible.
So, in a nutshell, data visualizations are critical because they transform raw data into actionable insights. They empower organizations to make data-driven decisions and better understand their landscapes in a more impactful way!. Now that you are able to perform basic data manipulation on Pandas you are ready to learn how develop visualizations supporting your analyses.
You will start using Seaborn, a software library that is useful to produce graphs and visualizations with few lines of code. You will learn how to represent data using Histograms, ScatterPlots, BoxPlots and BarPlots. Data Visualization is more art than science, each business manager has his/her preferred set of visualizations and you have to be prepared to accommodate to his/her preferences.
Happy plottings !!
8.1 What is seaborn?
Seaborn is a Python data visualization library built on top of Matplotlib. It provides a high-level interface for drawing visually appealing and informative representations of your data. Seaborn allows you to generate plots like scatter plots, bar plots, box plots, and heatmaps with just a few lines of code which is great for fast prototyping prior to the release of camera-ready dashboards. Seaborn integrates well with pandas data structures, making it a popular choice among data scientists and analysts.
Recent developments of alternative tools such as Plotly, Bokeh, Altair and others have made Seaborn somewhat obsolete yet it is still a great visualization library worth learning.
8.1.1 My first data visualization
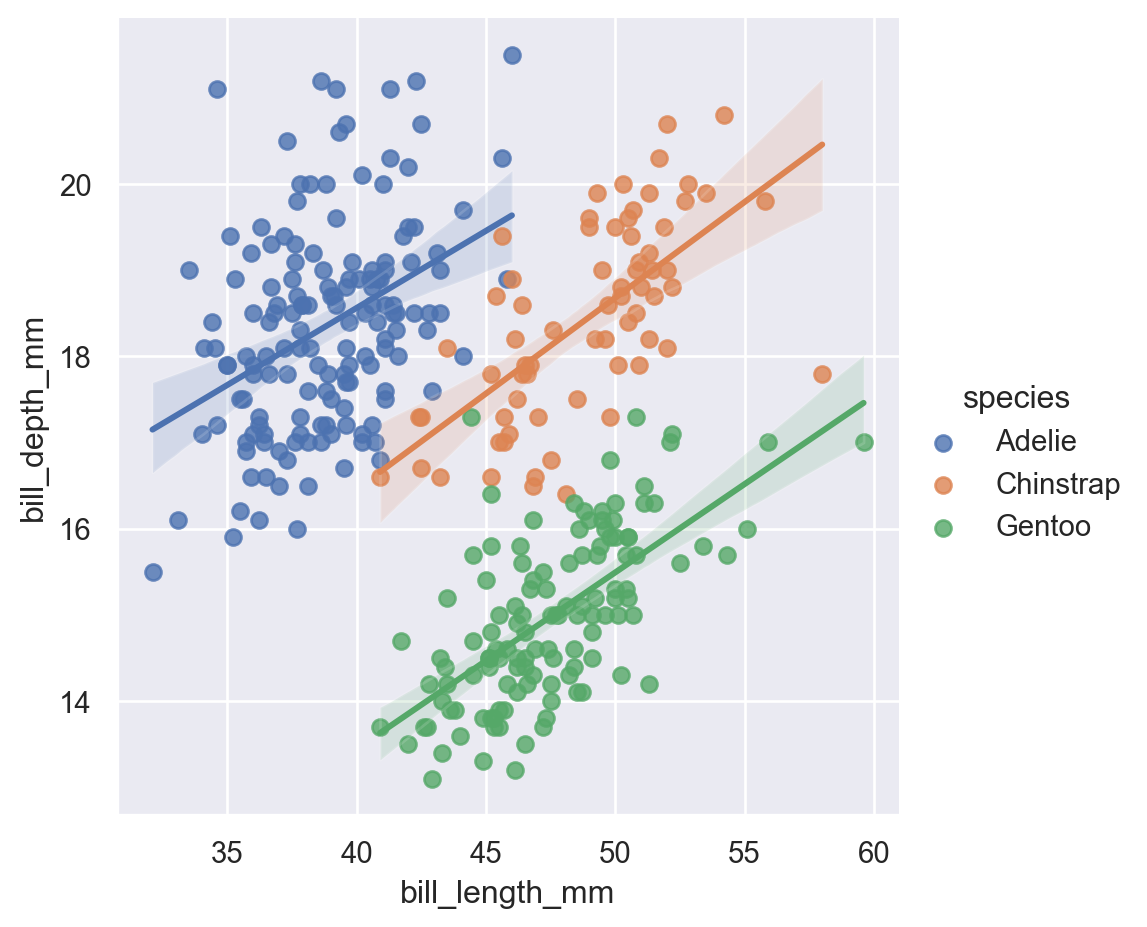
The following code provides an example of a visualization of the canonical penguins dataset. As you will notice, based on the visualization we conclude that penguins have different beak characteristics across species. This is useful, for instance, if you are trying to develop a machine learning based penguin classifier.
From a programming standpoint the code is, hopefully, easy to follow: (1) it reads the ‘penguins’ dataset into a Pandas DataFrame, (2) it relies on the seaborn method seaborn.lmplot() to produce a scatterplot representing the penguins’ beak characteristics across species. I can’t get any simpler than this! Therein lies the beauty of Seaborn.
import matplotlib%matplotlib inlineimport seaborn as snssns.set_theme()# Load the penguins datasetpenguins = sns.load_dataset("penguins")penguins.head()
When plotting continuous data using Seaborn, you have several effective visualization types at your disposal to reveal patterns and relationships in your data. One popular choice is the scatter plot, which allows you to visualize the correlation between two continuous variables, showcasing individual data points. If you want to observe the distribution and central tendency of a single continuous variable, a kde plot (Kernel Density Estimate) or a histogram can be used to illustrate the underlying frequency distribution. Another valuable option is the line plot, ideal for visualizing trends over time or sequences, often used with time series data
8.2.1 Histograms
Histograms are extremely useful to describe single continuous variables, they facilitate:
Distribution understanding: Use a histogram when you want to get a sense of how your data is distributed. It lets you see if the data is normally distributed, skewed, or if it has multiple peaks (bimodal, for example).
Outlier Identification: Histograms can help you spot outliers. If you notice that there are bins far removed from the main body of your data, these could be potential outliers worth investigating.
Comparing Distributions: If you have multiple groups and want to see how their distributions compare, you can overlay multiple histograms in a single plot by using different colors or transparency levels for each group. This helps to understand how different segments of your data behave.
Evaluating Changes in Data Over Time: If you’re working with time series data or repeated measures, plotting histograms for different time points or conditions can reveal how distributions shift over time.
A histogram is a bar plot where the axis representing the data variable is divided into a set of discrete bins and the count of observations falling within each bin is shown using the height of the corresponding bar.
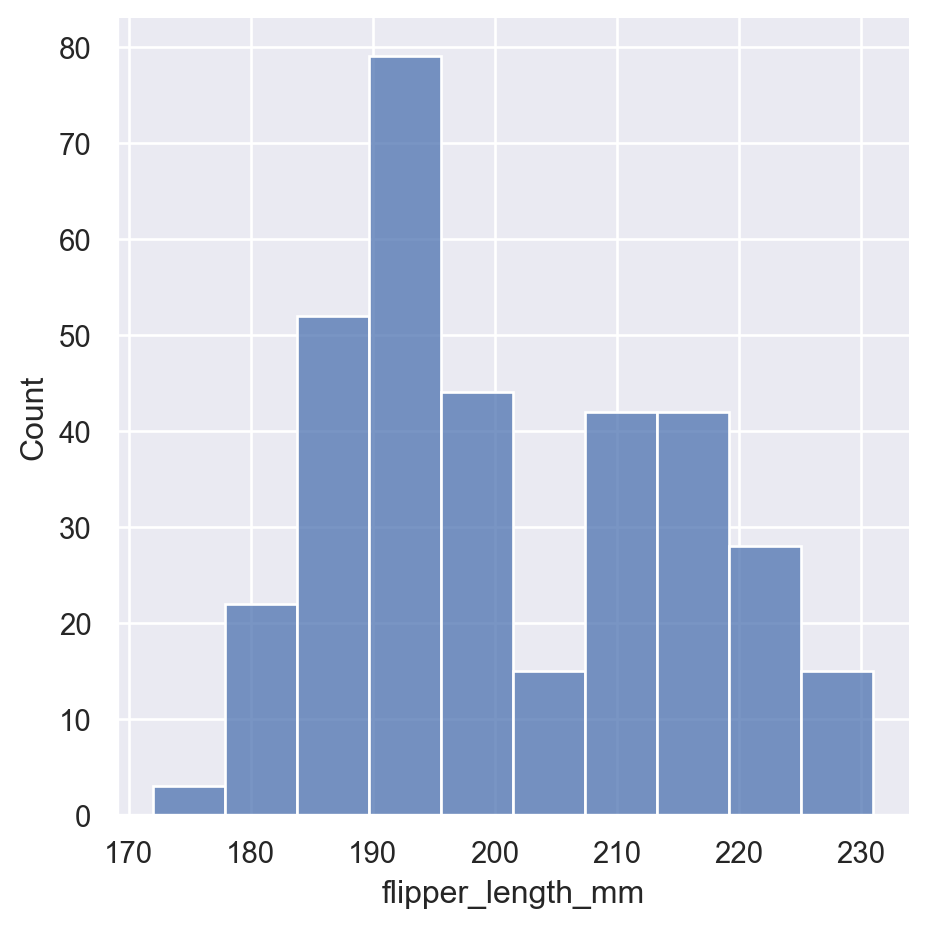
Building on our previous ‘penguins’ dataset, the following code provides an example of a histogram visualization using Seaborn’s seaborn.displot() method. Based on the figure we conclude that the most common flipper length is about 195 mm and that the variable ‘flipper length’ does not follow a normal distribution.
sns.displot(penguins, x="flipper_length_mm")
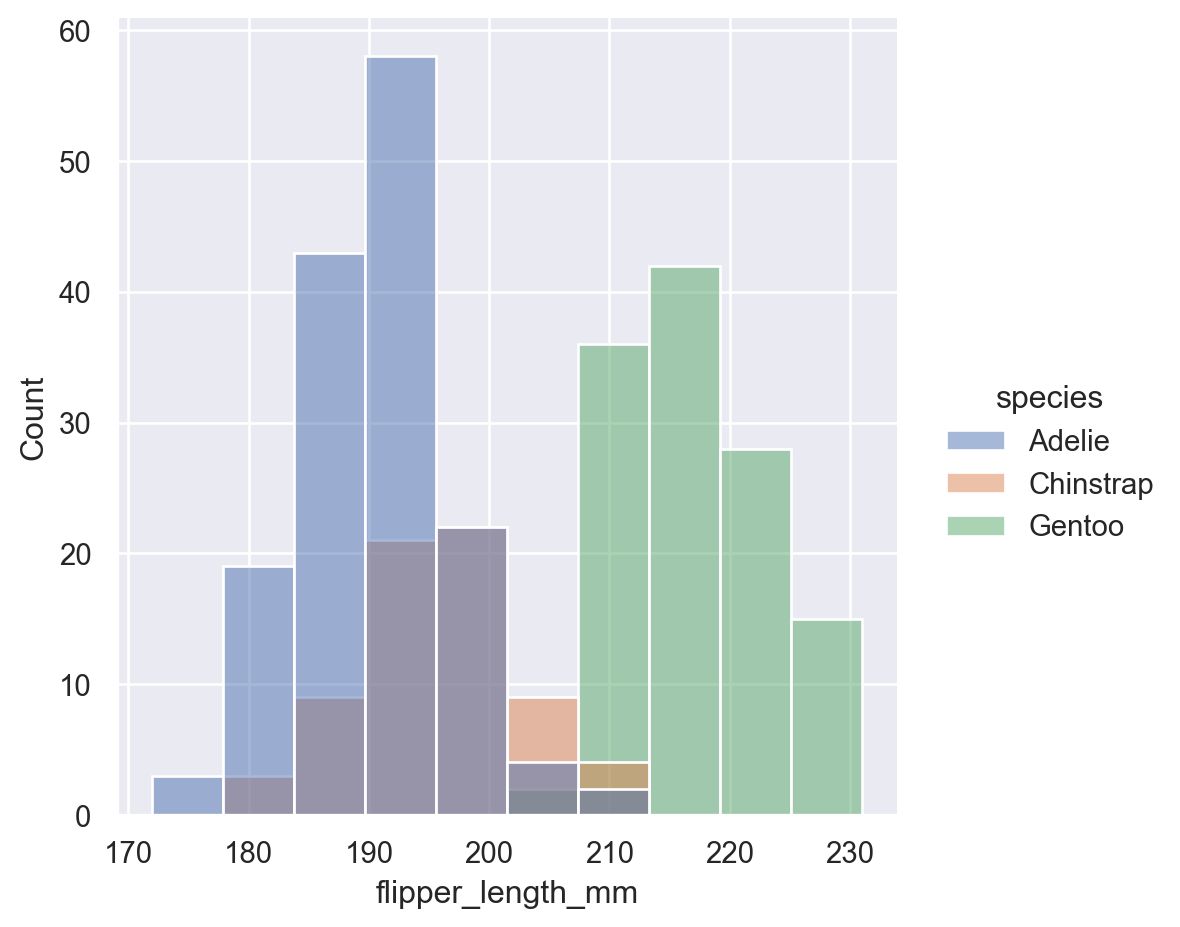
More interesting insights can be derived from the following visualization that represents the distribution of the variable flipper length for the three different species (‘Adelie’,‘Chinstrap’,‘Gentoo’)
I have always found quite useful to visualize the distributions of the variables I am going to consider in any statistical analysis. The method seaborn.distplot() is quite flexible, you can learn more about it at ‘Distplot’.
8.2.2 Scatter Plots
Scatter plots in Seaborn are useful visualizations to explore relationships between continuous variables. You might want to use them in a variety of scenarios:
Assessing Correlation: Scatter plots are perfect for evaluating the strength and direction of the relationship between two variables. If you suspect there is a correlation whether positive, negative, or none at all a scatter plot will make that visual relationship clear.
Identifying Patterns and Trends: When you want to visualize how one variable changes with respect to another, scatter plots help you see trends over time or across categories. For example, plotting a scatter plot of sales versus advertising spend can help you see the impact of marketing efforts on revenue.
Detecting Outliers: Scatter plots can also help highlight outliers. If a data point falls far outside the general pattern of other points, that is something to investigate further, and scatter plots visually capture those anomalies quite well.
*Visualizing Multi-Dimensional Data: If you have more than two continuous variables, you can create scatter plots with additional attributes, like point size (to represent a third variable) and color (for a fourth variable). This can provide a deeper insight into complex datasets.
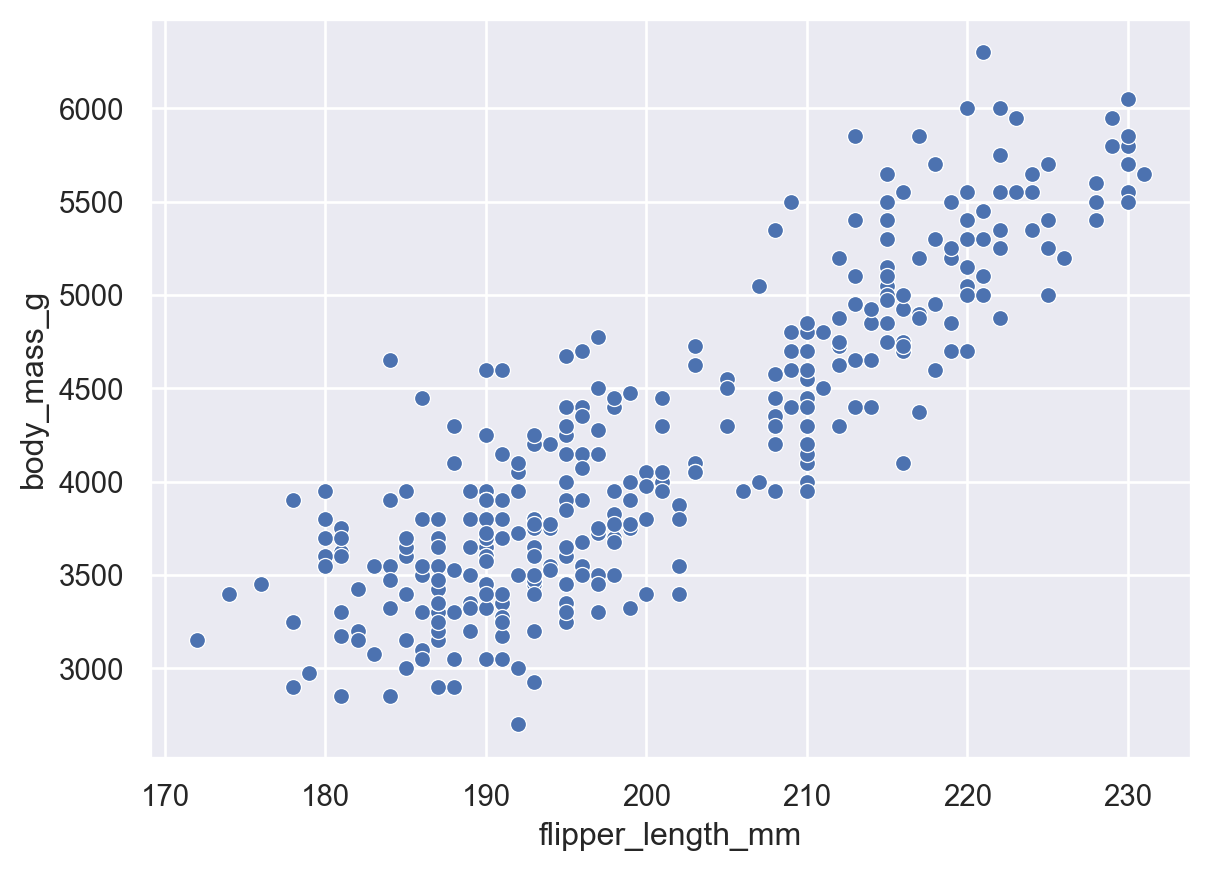
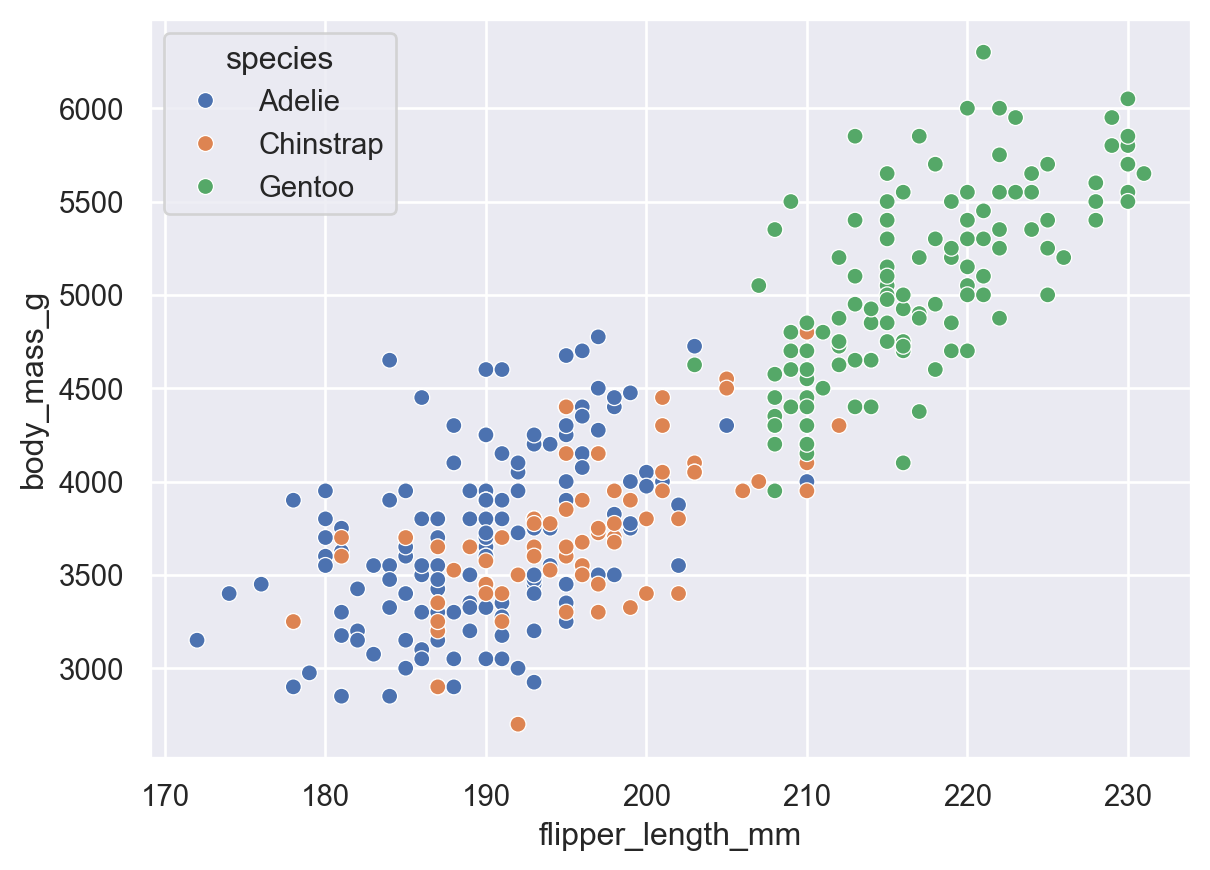
The following code provides and example of a histogram visualization using Seaborn’s seaborn.scatterplot() method. Based on the figure we conclude that there seems to be a linear relationship between flipper length and body mass.
Controlling for the type of penguin gives, however, a completely different story as shown in the following visualization. This time we observe that the relationship between body mass and flipper length is contingent on the type of penguin under consideration. This example provides an important lesson for aspiring data scientists: make sure you have invested sufficient time getting to know your dataset before attempting any statistical analysis.
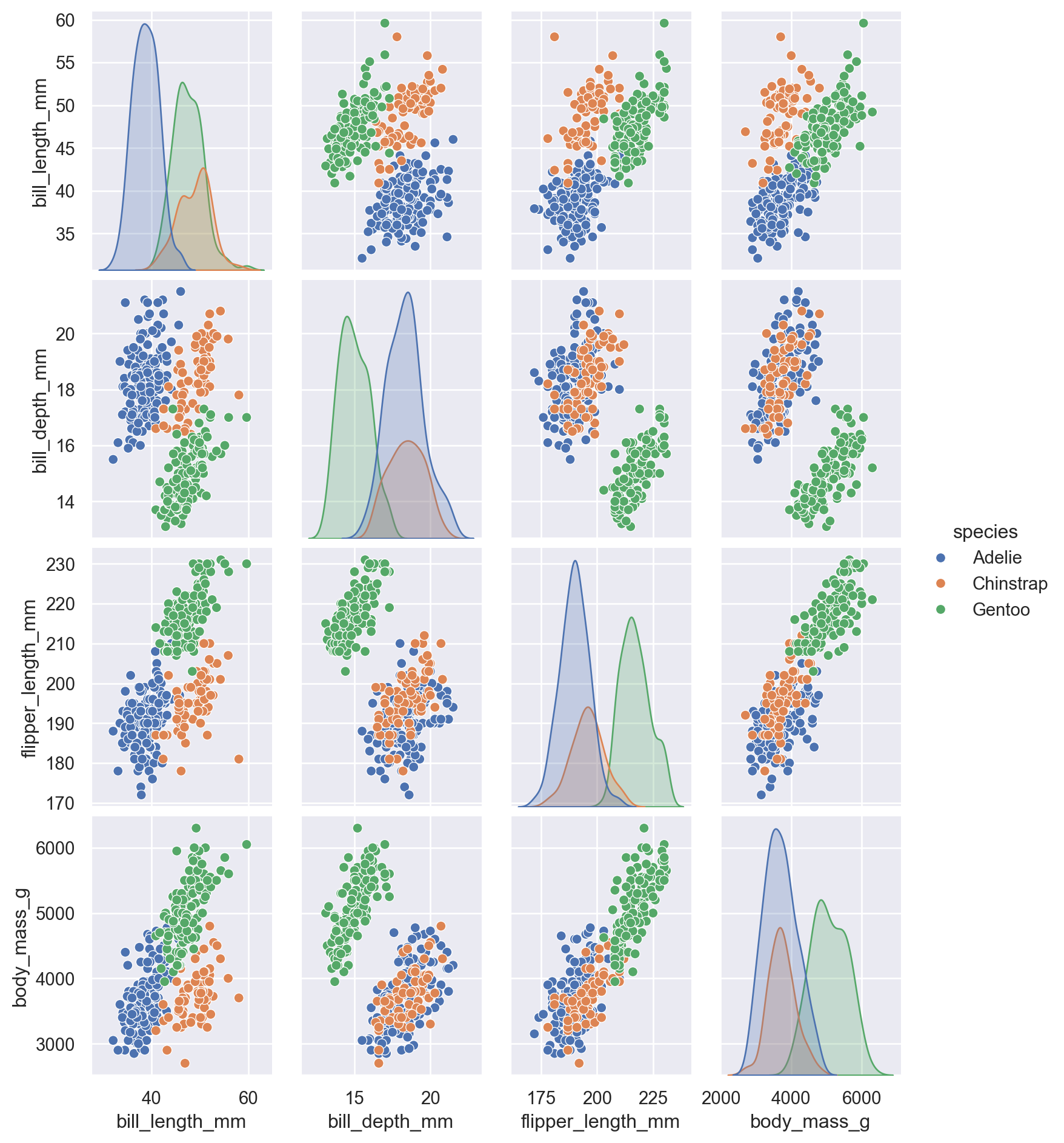
Pair plots in Seaborn are a powerful way to visualize the relationships among multiple variables in a dataset, particularly when you’re dealing with small or medium-sized datasets with several continuous variables. They are particularly useful during exploratory data analysis, helping you visualize correlations, distributions, and group comparisons all in one comprehensive view!
The following code computes a pair plot visualization for the penguins dataset. This visualization conveys relevant insights not only for data scientists but also machine learning engineers: we observe that the variables bill_length_mm’ and ‘bill_depth_mm’ are good candidates for a ML-based classifier as they ‘separate’ quite well the three species.
sns.pairplot(penguins, hue="species",aspect=0.8)
8.2.4 Line Plots
Line plots in Seaborn are particularly well-suited for visualizing trends over time or sequences, and they can be very effective in several contexts:
Time Series Data: If you have data collected over time (like sales figures, stock prices, or temperature readings), line plots are ideal. They help illustrate how a variable changes over time, making it easy to identify trends, seasonal patterns, and fluctuations.
Highlighting Patterns: Line plots can effectively show patterns, such as periodic fluctuations or trends, and are great for quickly interpreting the data’s behavior. Whether you are looking at gradual growth or sudden spikes, a line plot makes these aspects very clear.
Comparing Trends Across Groups: Line plots can effectively display multiple categories on the same graph. By using different lines (with varying colors or styles) for different groups, you can easily compare trends. For example, you could visualize how sales trends differ among various product lines over a year.
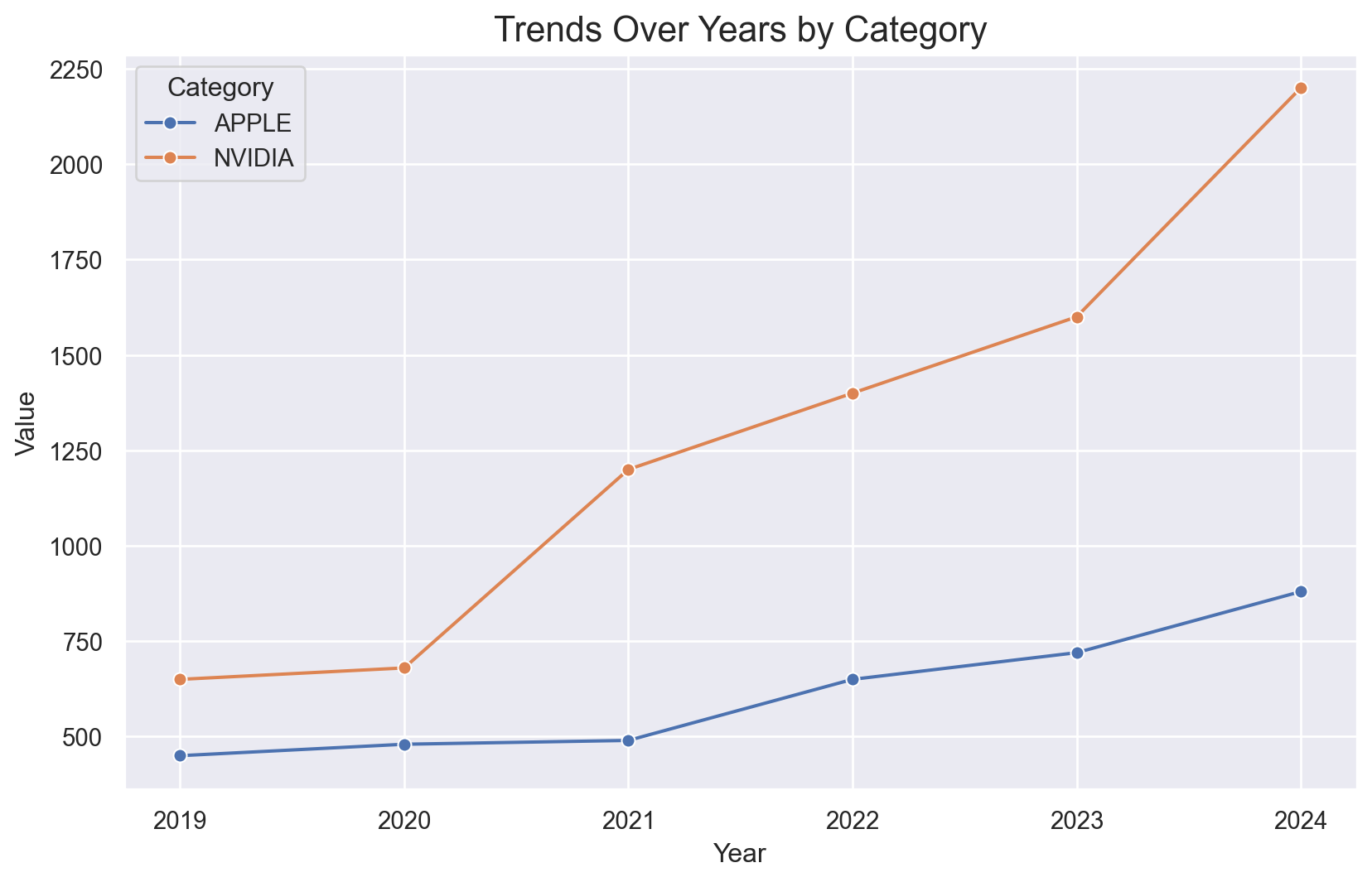
The following example illustrates how to develop line plot visualizations using seaborn.lineplot() method. In this case we fetch Apple and NVIDIA financial data and have it displayed in the same visualization. We notice the huge increase in NVIDIA’s market valuation in 2024.
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pd# Create a sample datasetdata = {'Year': [2019, 2020, 2021, 2022, 2023, 2024]*2,'Value': [450,480,490,650,720,880,650,680,1200,1400,1600,2200],'Category': ['APPLE'] *6+['NVIDIA']*6}stocksDataFrame = pd.DataFrame(data)# Create a lineplotplt.figure(figsize=(10, 6))sns.lineplot(data=stocksDataFrame, x='Year', y='Value', hue='Category', marker='o')# Customize the plotplt.title("Trends Over Years by Category", fontsize=16)plt.xlabel("Year", fontsize=12)plt.ylabel("Value", fontsize=12)plt.legend(title="Category")plt.grid(True)plt.show()
8.3 Discrete Data Visualizations
When plotting discrete data using Seaborn, you have several effective visualization options to convey categorical information clearly and intuitively. One common choice is the bar plot, which allows you to compare the size of different categories by representing their values with rectangular bars. This is particularly useful for showcasing count data or aggregated values across categories, such as sales figures or survey responses. Another great option is the count plot, which is a specific type of bar plot that automatically counts the occurrences of each category in your dataset, making it simple to visualize distributions of discrete variables. If you’re interested in showing the relationship between two discrete variables, a box plot or violin plot can be highly informative; box plots summarize the distribution of a numerical variable across different categories, while violin plots provide additional detail by showing the density of the data at different values. You could also use a strip plot or swarm plot to illustrate individual data points for a categorical variable, revealing distributions and potential overlaps in a visually engaging way.
8.3.1 Count Plots
Count plots in Seaborn are a specific type of bar plot that are especially useful for visualizing the frequency of occurrences of each category in a discrete variable. Count plots are popular visualizations given their simplicity. Count plots must be used, and interpreted, with caution to avoid misleading interpretations. As far as my experience goes there are always alternative visualizations better able to represent our insights and conclusions.
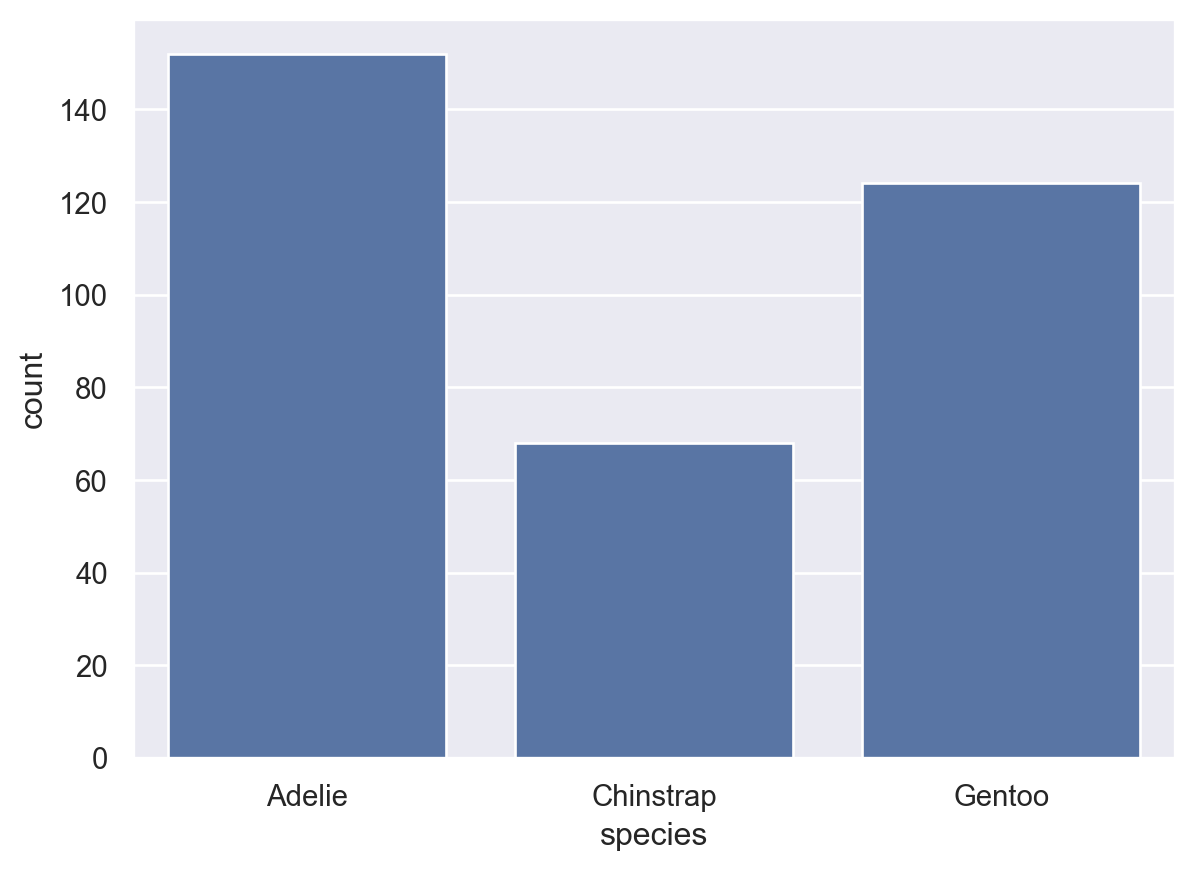
The following example illustrates how to develop count plot visualizations using seaborn.count() method. In this case we notice that, for the penguins dataset, Adelie penguins are the most frequent followed by Gentoo one
sns.countplot(penguins, x="species")
8.3.2 Bar Plots
Bar plots in Seaborn are a versatile visualization tool ideal for comparing the values of different categories or displaying aggregated data. Bar plots are useful when:
Comparing Categories: Bar plots excel at comparing the magnitude or frequency of different categories. For instance, if you want to compare sales figures across different product categories or survey results among various groups, a bar plot provides a clear visual representation of these comparisons.
Displaying Aggregated Data: When your data has been summarized (such as averages, sums, or counts), bar plots effectively showcase these aggregated values. For example, if you calculate the average test scores for different school classes, a bar plot can instantly convey how each class performs relative to others.
Highlighting Differences: If you need to emphasize specific differences between groups, bar plots can help illustrate these distinctions clearly. They allow easy identification of which categories stand out or underperform.
Showcasing Group Data: Bar plots allow you to compare multiple groups within the same category by using different colors for each group. This is useful in analyzing how subgroups behave overall or across categories, such as examining the performance of different departments within a company.
Simple and Intuitive Presentation: For reports or presentations where clarity is crucial, bar plots deliver straightforward visualizations that are easy to understand, making them suitable for audiences who may not have a technical background.
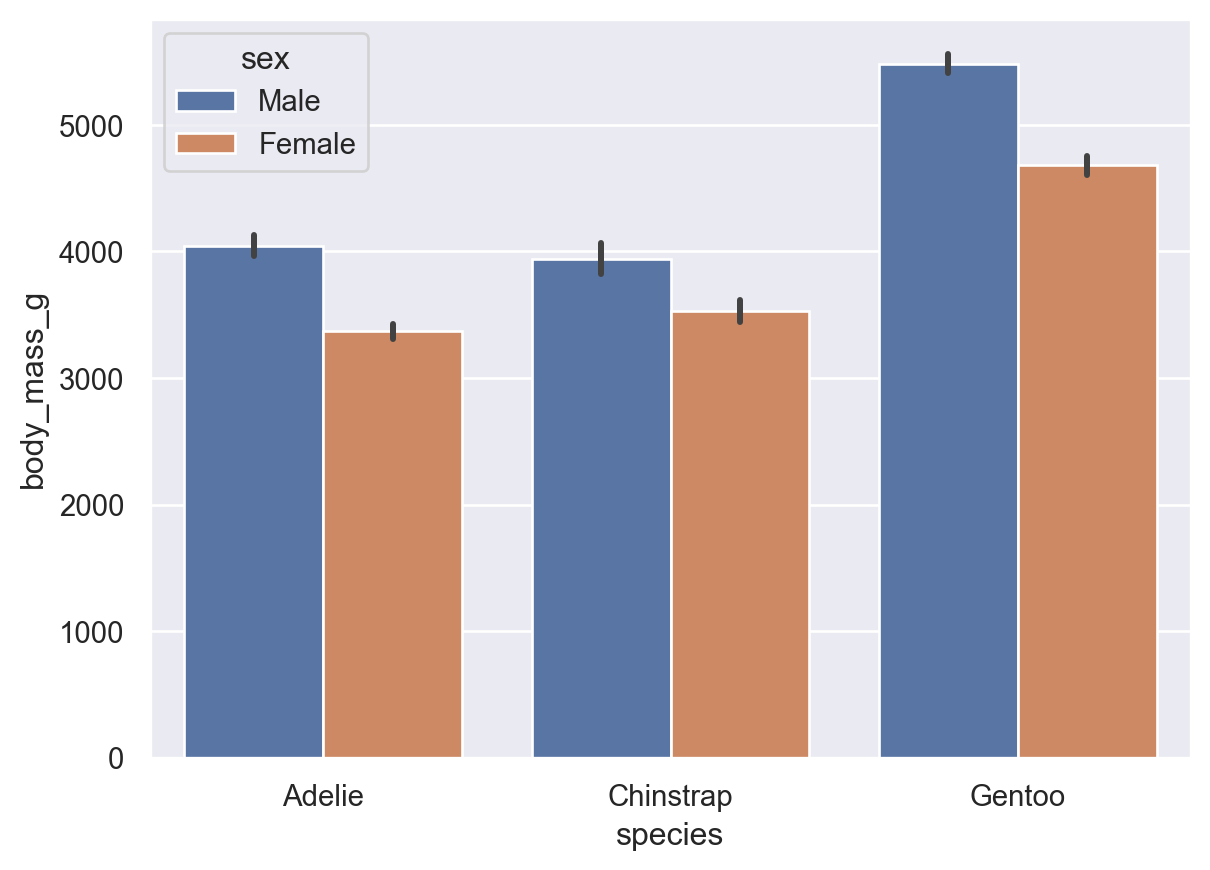
The following example illustrates how to develop bar plot visualizations using seaborn.barplot() method. In this case we notice that, for the penguins dataset, the mean of the variable body_mass_g is contingent on the gender and the type of penguin.
Boxplots are highly effective visualization tools used to summarize the distribution of a dataset and highlight key statistical properties. When employing Seaborn for data analysis and visualization, boxplots can be particularly useful under various circumstances: * Identifying Outliers: Boxplots excel in detecting outliers within your data. The data points that fall outside the ‘whiskers’ of a boxplot are potential outliers, making them easy to identify and investigate.
Comparing Distributions Across Categories: If you need to compare the distributions of a continuous variable across different categories or groups, boxplots are particularly useful. By displaying multiple boxplots side-by-side, it becomes straightforward to compare medians, interquartile ranges, and the presence of potential outliers across groups.
Summarizing Data Distribution: Boxplots provide a concise summary of a dataset’s distribution, highlighting important statistics such as the median, quartiles, and extremes. This enables a quick and effective overview without delving into detailed numerical summaries.
Handling Large Datasets: Boxplots manage large datasets efficiently by summarizing the data in a compact form. Unlike some other types of plots, boxplots do not become cluttered as the number of data points increases.
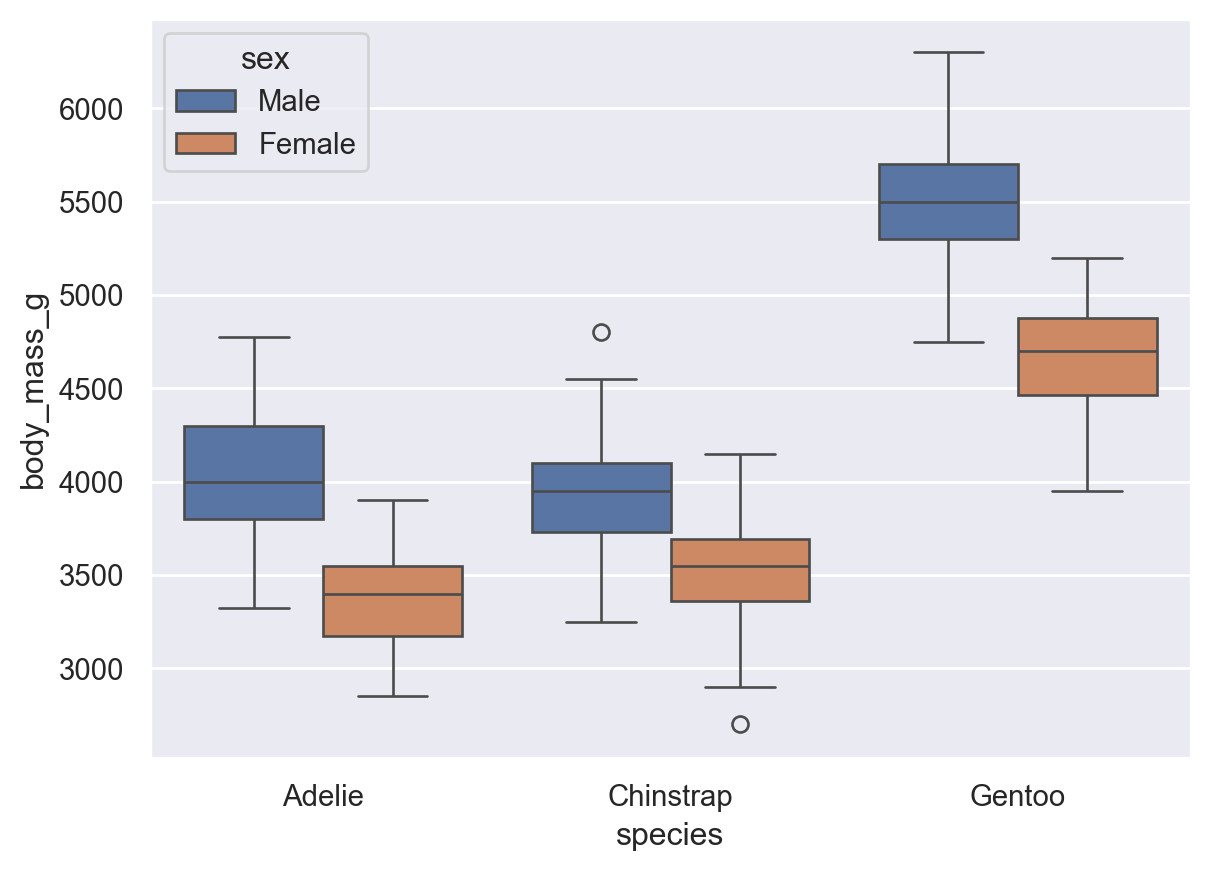
The following code displays the empirical distribution of the penguins’ body mass across species and gender. In Seaborn we use the method seaborn.boxplot().
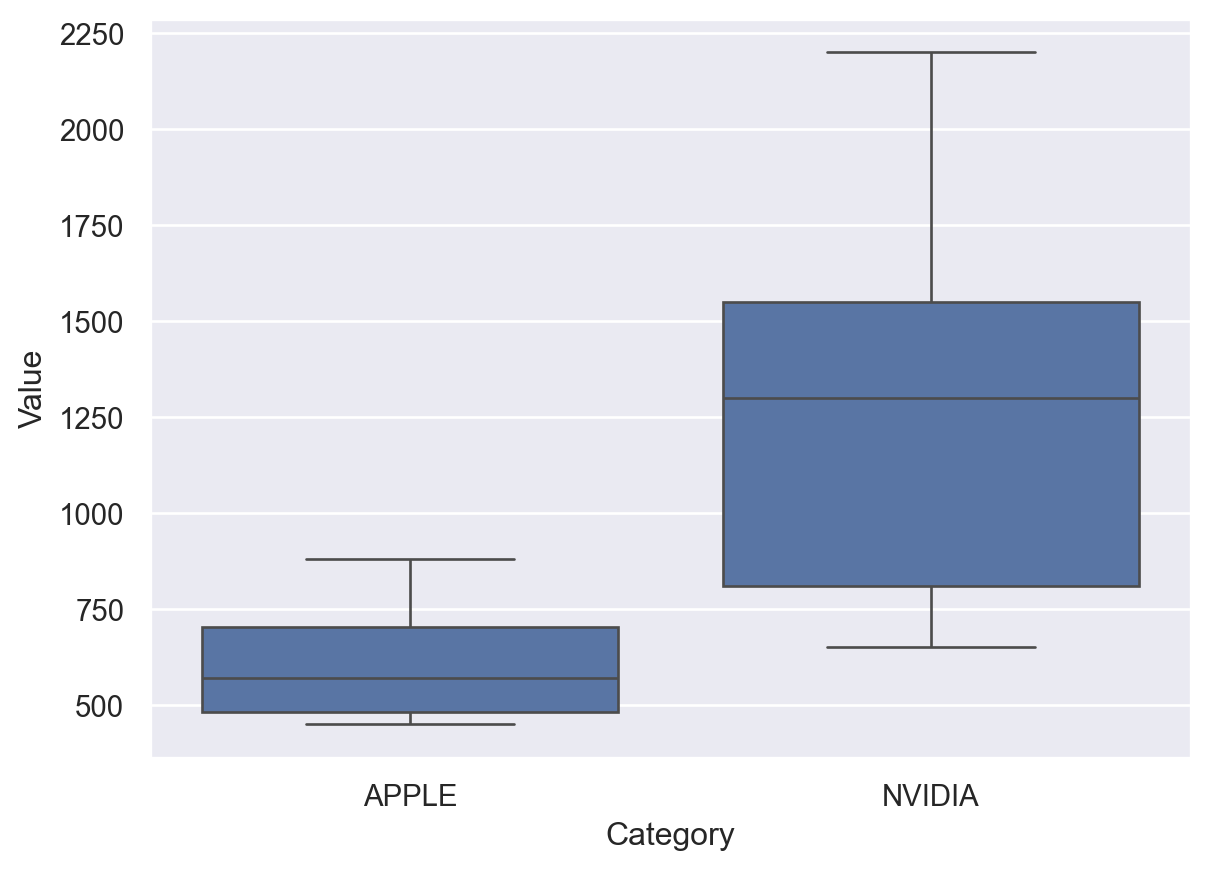
The following code displays the empirical distribution of the stocks’ yearly valuation for Apple and NVIDIA. We observe that NVIDIA’s stocks have larger valuation as well as volatility.
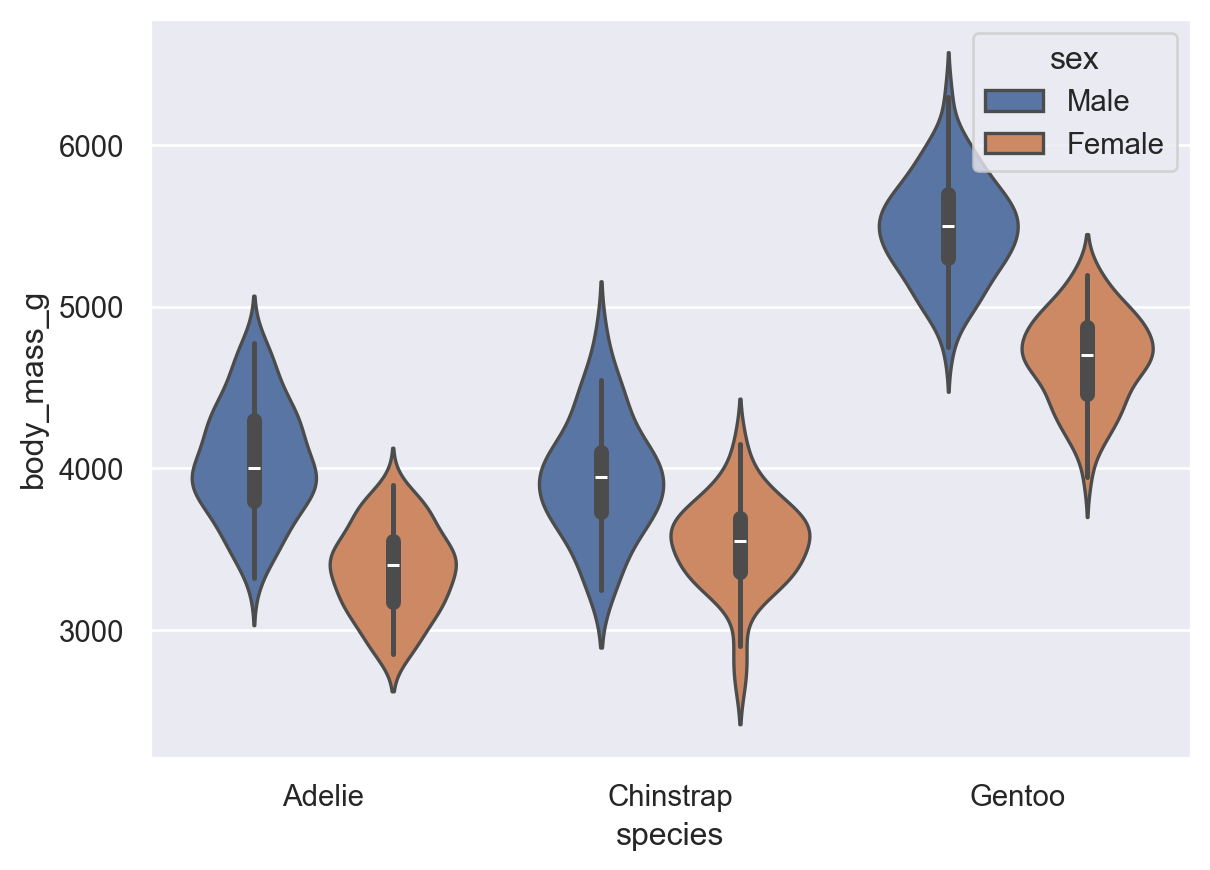
Violin Plots are quite similar to Box Plots; they summarize the distribution of variables and key statistical properties. The following code computes a violin plot outlining the statistical distribution of the variable body_mass_g for each gender and penguin type. In Seaborn we use the method seaborn.violinplot().
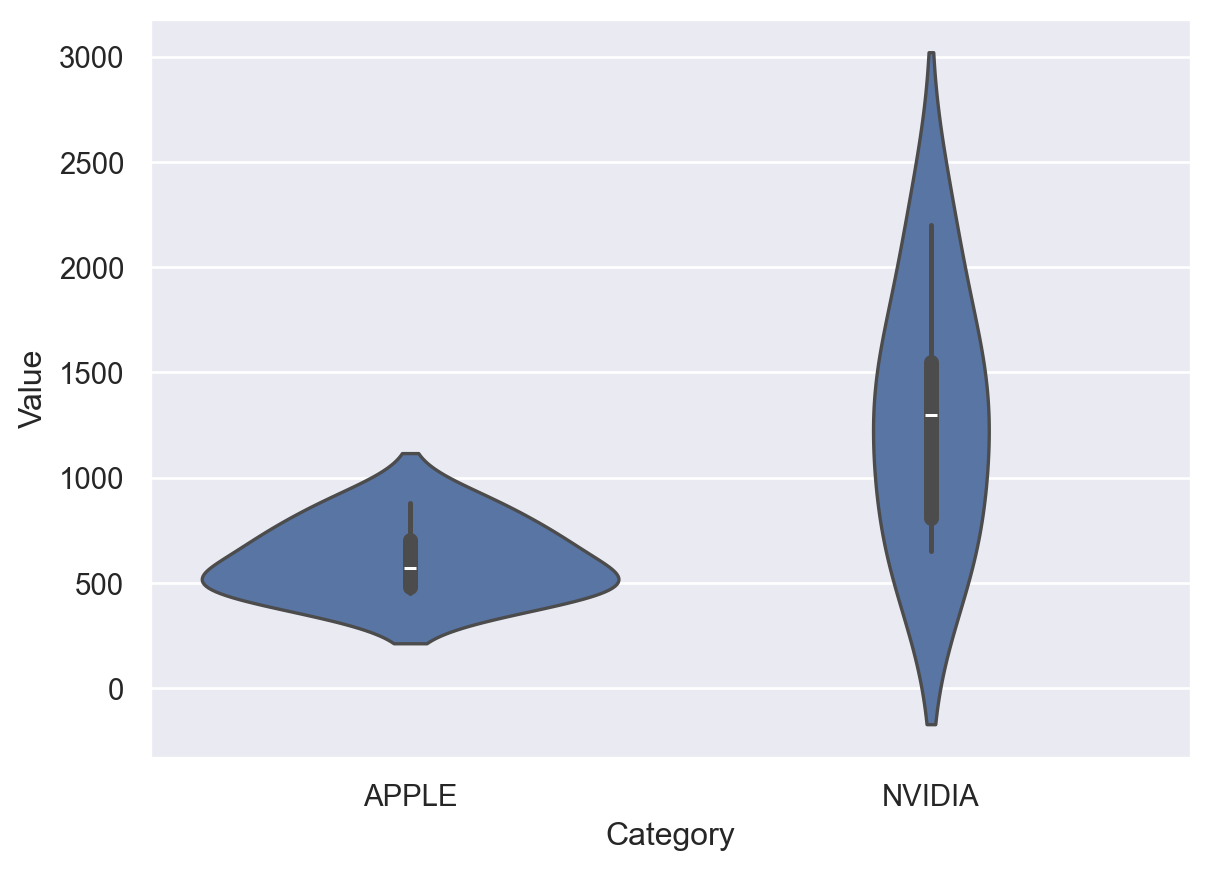
The following code displays the empirical distribution of the stocks’ yearly valuation for Apple and NVIDIA this time using violinplots visualizations.
The following Jupyter Notebook illustrates how to produce visualizations for the ‘tips’ dataset. As usual, try to understand the code, feel free to change it to have it customized to your preferences.
Second Example
The following Jupyter Notebook illustrates how to produce visualizations associated with a COVID19-related dataset.
Using Generative AI for coding purposes
In the previous example try the following prompt on Google Gemini:
“develop a boxplot visualization in seaborn displaying COVID19 deaths in Asia and America. Use a log scale”
Execute the code provided by Gemini, did it work?
Third Example
The following Jupyter Notebook provides examples of data processing and data visualization in a healthcare context.Please execute the code making sure that you understand how it works and the logic behind the analysis.
Once you have understood the code provided try to develop new code to answer the following: Develop a BarPlot Visualization of the Top10 most expensive Principal Diagnosis. Try to work it out on your own before checking the solutions below or asking Gemini for the solution to it
Code
import pandas as pdimport warningsimport numpy as npimport seaborn as snsfrom matplotlib import pyplot as pltHealthCareDataSet=pd.read_csv("https://github.com/thousandoaks/Python4DS-I/raw/main/datasets/HealthcareDataset_PublicRelease.csv",sep=',',parse_dates=['StartDate','EndDate','BirthDate'])PrincipalDiagnosisTotalExpenses=HealthCareDataSet.groupby('PrincipalDiagnosis')['TotalExpenses'].sum()PrincipalDiagnosisTotalExpenses.sort_values(ascending=False).head(10)sns.barplot(PrincipalDiagnosisTotalExpenses.sort_values(ascending=False).head(10))
Using Generative AI for coding purposes
In the previous example try the following prompt on Google Gemini:
“Develop a BarPlot Visualization of the Top10 most expensive Principal Diagnosis”
Worked like a charm, didn’t it ?
Now for another challenge, try to develop code for the following challenge: Develop a BoxPlot Visualization of the Top10 most expensive Principal Diagnosis.
Again try to work it out on your own before checking the solutions below (Tip: you need to define and apply a filter to extract those top10 most expensive categories)
Code
Top10DiagnosisbyTotalExpenses=PrincipalDiagnosisTotalExpenses.head(10).reset_index()## we apply a filter to keep only observations from the top10 list.top10Filter=HealthCareDataSet['PrincipalDiagnosis'].isin(Top10DiagnosisbyTotalExpenses['PrincipalDiagnosis'])HealthCareDataSet[top10Filter]sns.boxplot(HealthCareDataSet[top10Filter],x='PrincipalDiagnosis',y='TotalExpenses')
Using Generative AI for coding purposes
In the previous example try the following prompt on Google Gemini:
“Develop a BoxPlot Visualization of the Top10 most expensive Principal Diagnosis”
Hopefully it will return working code that is similar to what you developed on your own. Be cautious when using code provided by Generative AI, it is always advisable to run the code and check that it does as intended.
8.5 Conclusion
In this chapter we emphasize the critical role of data visualization in data science, highlighting its ability to simplify complex datasets, spot trends, communicate findings effectively, and support decision-making. In business and professional contexts, data visualizations are often more impactful than raw numbers or complex mathematical analyses, as they allow stakeholders to quickly grasp insights and make informed decisions. The chapter introduces Seaborn, a high-level Python visualization library built on Matplotlib, which integrates seamlessly with Pandas for producing aesthetically pleasing and informative plots.
The chapter provides a comprehensive overview of various visualization types using Seaborn, such as histograms, scatter plots, line plots, bar plots, and violin plots . Scatter plots are useful to assess correlations, histograms for understanding distributions, and line plots for analyzing trends over time. Advanced visualizations like pair plots, box plots, and violin plots are also covered, illustrating their use in summarizing distributions and comparing categories.
In the next chapter you will learn how to develop our own functions and have them applied to your datasets.
8.6 Further Readings
Developing effective visualizations requires practice and patience given the large amount of parameters involved (e.g. text style, colors, plot arrangement, etc).