The Big Book of Data Science (Part I)
Data Processing
1 Why Data Science?
")
Data science has become an essential pillar in today’s digital world, where we’re bombarded with a staggering amount of information daily. Data Science, -a mixed discipline that combines software programming, statistical analysis and mathematics-, allows you to process, transform and extract valuable insights from data.
Data science facilitates data-driven,fact-based, decision-making. By leveraging historical data, organizations can make more informed choices rather than relying on intuition or conjecture. This empirical approach enables businesses to identify market trends, forecast future events with greater accuracy, and align their strategies with customer behaviors and preferences. Consequently, companies can craft more effective and targeted marketing campaigns, optimize their product portfolios, and enhance overall competitiveness.
Data science significantly enhances customer insights, which is invaluable for any business striving to foster strong customer relationships and brand loyalty. Through sophisticated data analytics techniques, companies can segment their customer base, understand purchasing patterns, and extract insights that lead to highly personalized customer experiences. This personalization not only increases customer satisfaction and loyalty but also drives higher conversion rates and revenue growth. Understanding customer sentiment and feedback, facilitated by data science, allows companies to proactively address concerns, anticipate needs, and innovate continuously.
Operational efficiency is another area where data science delivers substantial benefits. By analyzing various operational metrics and employing predictive analytics, businesses can identify inefficiencies and implement measures to streamline processes. For instance, in supply chain management, data science enables precise demand forecasting and inventory optimization, reducing waste and lowering costs. Predictive maintenance, powered by data analytics, helps companies anticipate equipment failures and schedule maintenance activities proactively, minimizing downtime and enhancing productivity. Such optimizations contribute to a more robust and agile operational framework, which is crucial in today’s fast-paced business environment.
Data Science in the AI world
Data science is a critical component in the development and application of artificial intelligence (AI) systems, serving as the underpinning framework that allows AI to function effectively. Primarily, data science provides the essential fuel—data—that AI models require to learn and make inferences. Through processes such as data cleaning, preprocessing, and feature engineering, data scientists transform raw, often messy data into structured inputs suitable for training sophisticated AI algorithms. This ensures that the models operate on high-quality, relevant data, thereby enhancing their accuracy and reliability.
Additionally, data science contributes to the evaluation and validation of AI models, employing statistical techniques to guarantee that these models generalize well to new, unseen data and do not merely memorize the noise present in the training datasets.
Moreover, data science plays a vital role in making AI models interpretable and explainable. While AI, particularly deep learning models, can often appear as opaque black boxes, data scientists employ various methods to clarify the inference processes of AI-based models. This is crucial for building trust and ensuring the models’ decisions are transparent.
2 Data Science in Practice
Data Science is a vast field involving systems, software, statistics, visualization and storytelling among others. From a practical standpoint data intensive endeavours, including the training and operation of AI-based services, usually proceed through the following stages, refer to the following figure.
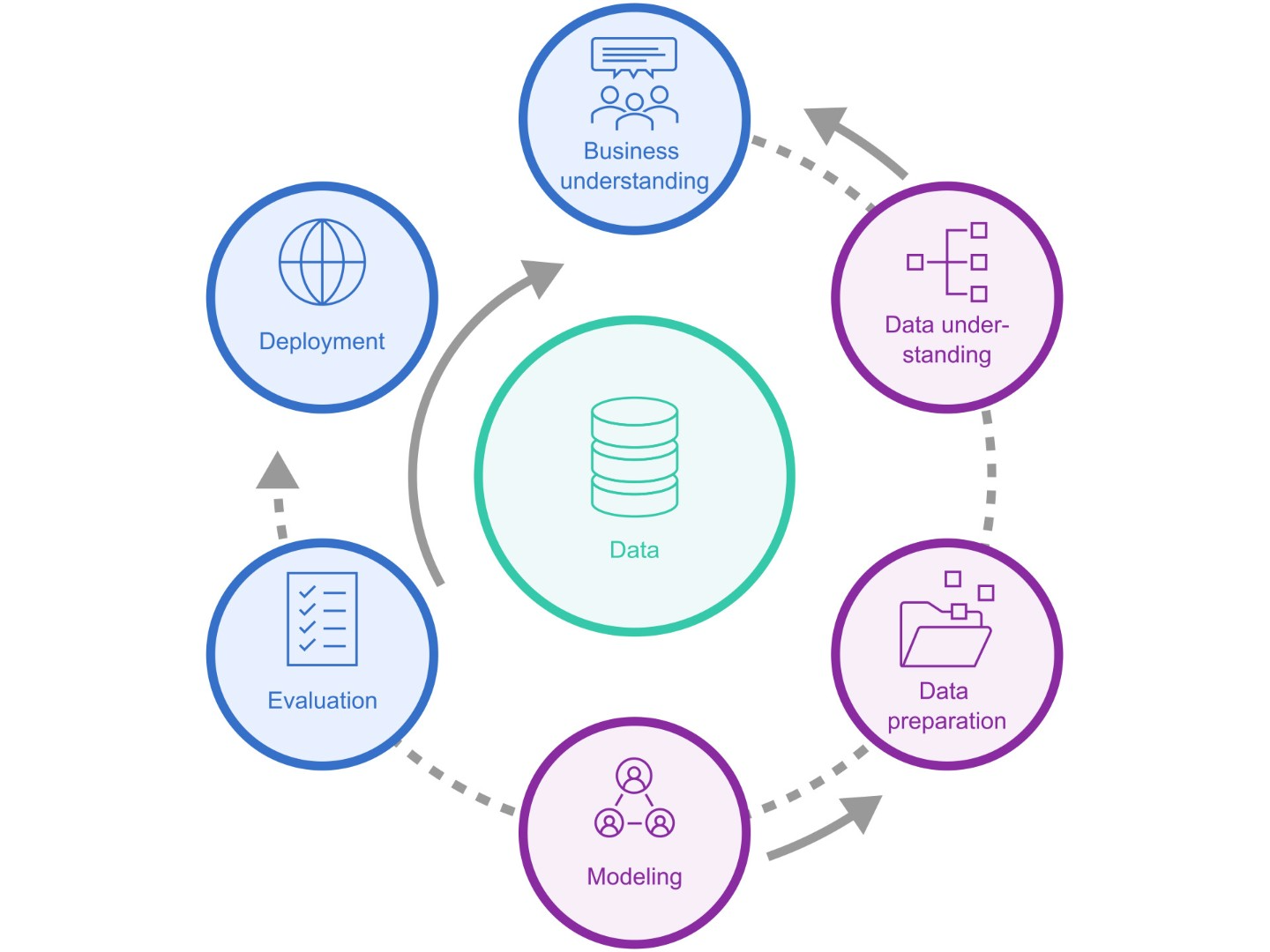
Business Understanding: This initial phase focuses on comprehending the business objectives and requirements. It involves defining the project goals from a business perspective and formulating the problem in a clear and actionable manner (e.g. customer churning rate, recommender system). This step ensures alignment between the data related project and the overarching business strategy.
Data Understanding: In this phase, data collection and initial exploration are performed to familiarize oneself with the data. This includes assessing data quality, identifying data characteristics, and uncovering initial insights. The main purpose is to gain a deep understanding of the data that will be used for analysis. I cannot emphasize enough the importance of having a solid understanding of the data and the underlying business processes prior to any modeling attempt.
Data Preparation: Data preparation involves all activities necessary to construct the final dataset. This typically entails data cleaning, transformation, integration, and formatting. The aim is to prepare the data in a suitable form for use in the modeling phase, addressing issues such as missing values, outliers, and inconsistencies.
Modeling: During the modeling phase, various analytical techniques and algorithms are selected and applied to the prepared data (e.g. lineal regression, decision trees, deep learning). This involves building and fine-tuning models to extract patterns and insights. Experimentation with different models may be necessary to determine the most effective approach.
Evaluation: The evaluation phase assesses the performance and validity of the constructed models (e.g. accuracy, precision, recall, \(R^2\)). It involves verifying whether the model meets the business objectives defined in the initial phase. This includes considering both quantitative metrics and qualitative assessments to ensure the results are accurate and reliable.
Deployment: In the final phase, the results are deployed into the operational environment. This can involve integrating the model into business processes, creating reports, dashboards or deployment of an AI-based inference engine, and ensuring the findings are accessible and actionable for stakeholders. It may also include monitoring and maintenance of the model to ensure its continued effectiveness over time.
3 Why this book?
There are already excellent books on software programming for data processing and data transformation for instance: Wes McKinney’s. This book, reflecting on my own industrial and teaching experience, tries to overcome the big learning curve newcomers to the field have to travel before they are ready to tackle real data science and AI challenges. In this regard this book is different to other books in that:
It assumes zero software programming knowledge. This instructional design is intentional given the book’s aim to open the practice of data science to anyone interested in data exploration and analysis irrespective of their previous background.
It follows an incremental approach to facilitate the assimilation of, sometimes, arcane software techniques to manipulate data.
It is practice oriented to ensure readers can apply what they learn in their daily practices.
Illustrates how to use generative AI to help you become a more productive data scientist and AI engineer.
By reading and working on the labs included in this book you will develop software programming skills required to successfully contribute to the data understanding and data preparation stages involved in any data related project. You will become proficient at manipulating and transforming datasets in industrial contexts and produce clean, reliable datasets that can drive accurate analysis and informed decision-making. Moreover you will be prepared to develop and deploy dashboards and visualizations supporting the insights and conclusions in the deployment stage.
Data modelling and evaluation are not covered in this book. We are working on a second installment of the book series illustrating the application of statistical and machine learning techniques to derive data insights.
4 Why Python?
The Python versus R debate is as old as the field of data science with yet new languages (e.g. Julia, Rust, Scala) joining the fray. Each language has its own strengths and weaknesses, and the right choice really depends on what you’re trying to accomplish. Are you in need of real time analytics? Do you need highly specialized numerical applications ?
Python has emerged as the leading language in data science and AI primarily due to its simplicity and readability. Its clean syntax allows data scientists and analysts to write and understand code quickly, which is essential when dealing with complex data analyses. This ease of use significantly lowers the barrier for newcomers, enabling them to focus on data interpretation and insight generation rather than getting bogged down by intricate coding nuances.
Another major factor contributing to Python’s dominance is its rich ecosystem of libraries and frameworks tailored for various aspects of data science and AI. Libraries like Pandas for data manipulation, NumPy for numerical computations, Scikit-learn for machine learning, and TensorFlow and PyTorch for deep learning provide specialized tools that save time and enhance efficiency. This extensive library support means that common tasks can be performed with minimal code, allowing data scientists to iterate and experiment quickly.
Lastly, Python boasts a robust community and broad industry adoption, which further solidifies its position. With countless resources available, from tutorials to forums, help is always at hand for troubleshooting and learning new techniques.
In the end, it’s not so much about which one is the best universally; it’s about context. What kind of projects are you working on? What’s your team’s expertise? There’s room for multiple languages in the toolbox of a data scientist, so don’t be afraid to mix and match depending on your needs!
5 Why cloud computing?
We decided from the start to rely on cloud computing for the delivery of the books’s labs and examples as this significantly eases the learning experience for readers. With cloud services, there’s no need for them to install and maintain applications on their personal devices, which greatly lessens the learning curve. Instead, readers can focus their energy on engaging with the material and developing their skills without getting bogged down by technical complications. Moreover, this approach enables seamless use of emerging technologies, such as generative AI, allowing our learners to stay current with the latest advancements in data science and fully explore their potential.
Embracing cloud computing as the technological platform not only enhances our instructional delivery but also prepares our students for the demands of a technology-driven job market.
6 How to read this book?
In my experience each reader has his/her own particular reading style. This book proceeds incrementally in the development of software programming skills involved in data transformation and data processing. Those with little experience in Python will surely benefit from a sequential reading approach making sure they spend sufficient time running and understanding the examples and labs they run into. Readers with moderate experience in applying Python for data science purposes might prefer to read only those chapters that touch upon new concepts or techniques.
Whenever possible try to apply the concepts you learn into your daily work practice as (1) it will keep you motivated to code on a regular basis as well as (2) make you proficient in the manipulation of real data to deliver real value to others.
Becoming proficient in software programming, like any other human language, requires patience and persistence. As the old motto goes: “Practice Makes Perfect”.
Happy codings!