import plotly.express as px
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species", title="Iris Dataset Scatter Plot using Plotly Express")
fig.show()20 Advanced Data Visualization
In today’s data-driven world, dashboards and interactive visualizations are essential tools for turning raw data into actionable insights. They provide a dynamic and intuitive way to present complex information, enabling decision-makers to quickly identify trends, anomalies, and key metrics. Interactive visualizations allow users to explore data in real-time, filtering and drilling down to uncover insights tailored to their needs. Dashboards consolidate diverse data points into a single interface, making them invaluable for monitoring business performance, tracking KPIs, and sharing findings with stakeholders. This ability to engage with data visually fosters better understanding and faster decision-making, bridging the gap between technical analysis and practical application.
Advanced visualizations in data science create visual narratives that go beyond static charts. Geolocated data, for example, enables the representation of spatial information, making it possible to map patterns such as customer distributions, logistics flows, or regional sales performance. These visualizations bring context to the numbers, revealing relationships and trends that might be missed in traditional formats. Advanced techniques like multi-dimensional visualizations, network diagrams, and animated charts empower data scientists to communicate intricate relationships and temporal changes with clarity. As data complexity grows, advanced visualizations ensure that insights remain accessible, meaningful, and impactful, serving as a cornerstone of modern data science.
20.1 What is Plotly?
Plotly is an open-source graphing library that provides tools for creating interactive, web-based visualizations in Python, R, JavaScript, and other programming languages. Plotly is widely used in data science, analytics, and web development for producing high-quality, shareable, and interactive data visualizations.
Seaborn, the visualization library you studied in Chapter 8 provided barebones visualization capabilities. Plotly offers advanced functionalities such as:
- Interactivity: Plotly charts are interactive by default, allowing users to zoom, pan, hover over data points, and explore visualizations dynamically.
- Wide Range of Chart Types: Plotly supports an extensive variety of visualizations, including standard chart types (scatter, line, bar), advanced statistical plots, 3D plots, geospatial maps, and specialized visualizations like heatmaps, choropleth maps, and candlestick charts.
- Web-Based Visualizations: Built for the web, Plotly visualizations are rendered as HTML, making them easy to embed in websites, Jupyter notebooks, dashboards, and applications.
- Integrations with Dash: Plotly serves as the core visualization library for Dash, a Python framework for building interactive, analytical web applications. This enables users to create fully interactive dashboards and web apps.
- Declarative API: Plotly’s high-level API, Plotly Express, provides a quick, simplified syntax for producing common visualizations with minimal code, ideal for rapid data exploration.
20.2 Plotly-based Visualizations
Plotly provides two alternatives to develop visualizations in Python:
- Plotly Express: A high-level interface in Plotly for creating common visualizations with minimal code. It’s great for quick, exploratory analysis and allows users to build plots in just one line.
- Plotly Graph Objects: A lower-level, more detailed API in Plotly that provides complete control over every element of the chart, enabling complex customization and highly interactive plots.
The following two examples illustrates the differences between both alternatives. Plotly Express requires less code whereas Plotly Graph Objects allow you higher levels of customization.
import plotly.graph_objects as go
df = px.data.iris()
fig = go.Figure()
# Add traces for each species
for species in df['species'].unique():
species_data = df[df['species'] == species]
fig.add_trace(go.Scatter(
x=species_data['sepal_width'],
y=species_data['sepal_length'],
mode='markers',
name=species
))
# Customize layout
fig.update_layout(
title="Iris Dataset Scatter Plot using Graph Objects",
xaxis_title="Sepal Width",
yaxis_title="Sepal Length"
)
fig.show()
Plotly Express v.s. Plotly Graph Objects
For obvious reasons it is advisable to try Plotly Express in the first place reverting to Plotly Graph Objects whenever further customization is required.
The following table summarizes available visualizations in both Plotly Express and Plotly Graph Objects
| Visualization Type | Description | Plotly Express Function | Plotly Graph Object Class |
|---|---|---|---|
| Scatter Plot | Displays individual data points. | px.scatter() |
go.Scatter |
| Line Plot | Shows trends over a continuous interval or time period. | px.line() |
go.Scatter (with mode='lines') |
| Bar Plot | Compares categorical data with rectangular bars. | px.bar() |
go.Bar |
| Histogram | Shows the frequency distribution of a continuous variable. | px.histogram() |
go.Histogram |
| Box Plot | Summarizes data distribution with quartiles and outliers. | px.box() |
go.Box |
| Violin Plot | Combines KDE with box plot features to show distributions. | px.violin() |
go.Violin |
| Strip Plot | Shows data distribution along one continuous axis. | px.strip() |
go.Scatter (with mode='markers') |
| Pie Chart | Displays parts of a whole as slices of a pie. | px.pie() |
go.Pie |
| Sunburst Chart | Hierarchical visualization of part-to-whole relationships. | px.sunburst() |
go.Sunburst |
| Treemap | Visualizes hierarchical data as nested rectangles. | px.treemap() |
go.Treemap |
| Funnel Chart | Shows stages in a process (e.g., sales pipeline). | px.funnel() |
go.Funnel |
| Area Plot | Similar to line plot but filled under the line. | px.area() |
go.Scatter (with fill='tozeroy') |
| Density Heatmap | 2D representation of data density using color intensity. | px.density_heatmap() |
go.Heatmap |
| Density Contour | Shows data density with contour lines. | px.density_contour() |
go.Contour |
| Scatter Matrix | Matrix of scatter plots showing relationships between multiple variables. | px.scatter_matrix() |
go.Splom |
| Parallel Coordinates | Multi-dimensional data visualization using parallel axes. | px.parallel_coordinates() |
go.Parcoords |
| Parallel Categories | Categorical parallel coordinates for multi-dimensional data. | px.parallel_categories() |
go.Parcats |
| Map Plot (Scatter) | Maps geographic data points on a map. | px.scatter_mapbox(), px.scatter_geo() |
go.Scattergeo, go.Scattermapbox |
| Choropleth Map | Displays values for geographic areas using color intensity. | px.choropleth(), px.choropleth_mapbox() |
go.Choropleth |
| 3D Scatter Plot | 3D scatter plot to show three-dimensional data points. | px.scatter_3d() |
go.Scatter3d |
| 3D Line Plot | 3D line plot for three-dimensional data. | px.line_3d() |
go.Scatter3d (with mode='lines') |
| 3D Surface Plot | Visualizes 3D data as a surface. | N/A | go.Surface |
| Heatmap | 2D heatmap of matrix-like data. | N/A | go.Heatmap |
| Waterfall Chart | Shows cumulative changes in a value across steps. | N/A | go.Waterfall |
| Candlestick Chart | Financial plot showing open, high, low, and close values. | N/A | go.Candlestick |
Scatter Plots
With px.scatter(), each data point is represented as a marker point, whose location is given by the x and y columns
import plotly.express as px
df = px.data.iris()
df.head()| sepal_length | sepal_width | petal_length | petal_width | species | species_id | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa | 1 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa | 1 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa | 1 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa | 1 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa | 1 |
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species", symbol="species")
fig.show()Scatter plots with variable-sized circular markers are often known as bubble charts. Note that color and size data are added to hover information. You can add other columns to hover data with the hover_data argument of px.scatter().
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species",
size='petal_length', hover_data=['petal_width'])
fig.show()Color can also be used to code continuous variables, for instance:
fig = px.scatter(df, x="sepal_width", y="sepal_length", color='petal_length')
fig.show()Face plots are quite useful for exploratory data analysis. Facet plots, also known as trellis plots or small multiples, are figures made up of multiple subplots which have the same set of axes, where each subplot shows a subset of the data, for instance:
fig = px.scatter(df, x="sepal_width", y="sepal_length", facet_col='species')
fig.show()Plotly Express allows you to add Ordinary Least Squares regression trendline to scatterplots with the trendline argument.
fig = px.scatter(df, x="sepal_width", y="sepal_length", trendline='ols')
fig.show()Plotly Express also supports non-linear LOWESS trendlines.
df = px.data.stocks(datetimes=True)
fig = px.scatter(df, x="date", y="GOOG", trendline="lowess", trendline_options=dict(frac=0.1))
fig.show()Plotly Express can leverage Pandas’ rolling, ewm and expanding functions in trendlines as well, for example to display moving averages. Values passed to trendline_options are passed directly to the underlying Pandas function
df = px.data.stocks(datetimes=True)
fig = px.scatter(df, x="date", y="AAPL", trendline="rolling", trendline_options=dict(window=5),
title="5-point moving average")
fig.show()Bar Charts
Bar Charts can be developed with px.bar(). Each data point is represented as a marker point, whose location is given by the x and y columns.
df = px.data.stocks(indexed=True)-1
df.head()| company | GOOG | AAPL | AMZN | FB | NFLX | MSFT |
|---|---|---|---|---|---|---|
| date | ||||||
| 2018-01-01 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2018-01-08 | 0.018172 | 0.011943 | 0.061881 | -0.040032 | 0.053526 | 0.015988 |
| 2018-01-15 | 0.032008 | 0.019771 | 0.053240 | -0.029757 | 0.049860 | 0.020524 |
| 2018-01-22 | 0.066783 | -0.019943 | 0.140676 | 0.016858 | 0.307681 | 0.066561 |
| 2018-01-29 | 0.008773 | -0.082857 | 0.163374 | 0.018357 | 0.273537 | 0.040708 |
fig = px.bar(df, x=df.index, y="GOOG")
fig.show()import plotly.express as px
df = px.data.iris()
fig = px.bar(df, x="sepal_width", y="sepal_length", color="species")
fig.show()The default stacked bar chart behavior can be changed to grouped (also known as clustered) using the barmode argument:
fig = px.bar(df, x="sepal_width", y="sepal_length", color="species",barmode='group')
fig.show()Line Charts
Time series can be represented using px.line() and px.area()
df = px.data.stocks()
fig = px.line(df, x='date', y="GOOG")
fig.show()fig = px.line(df, x="date", y=df.columns,
hover_data={"date": "|%B %d, %Y"},
title='custom tick labels')
fig.update_xaxes(
dtick="M1",
tickformat="%b\n%Y")
fig.show()df = px.data.stocks(indexed=True)-1
fig = px.area(df, facet_col="company", facet_col_wrap=2)
fig.show()A range slider is a small subplot-like area below a plot which allows users to pan and zoom the X-axis while maintaining an overview of the chart.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
fig = px.line(df, x='Date', y='AAPL.High', title='Time Series with Rangeslider')
fig.update_xaxes(rangeslider_visible=True)
fig.show()Range selector buttons are special controls that work well with time series and range sliders, and allow users to easily set the range of the x-axis
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
fig = px.line(df, x='Date', y='AAPL.High')
fig.update_xaxes(
rangeslider_visible=True,
rangeselector=dict(
buttons=list([
dict(count=1, label="1m", step="month", stepmode="backward"),
dict(count=6, label="6m", step="month", stepmode="backward"),
dict(count=1, label="YTD", step="year", stepmode="todate"),
dict(count=1, label="1y", step="year", stepmode="backward"),
dict(step="all")
])
)
)
fig.show()Bubble Charts
A bubble chart is a scatter plot in which a third dimension of the data is shown through the size of markers.
import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(df.query("year==2007"), x="gdpPercap", y="lifeExp",
size="pop", color="continent",
hover_name="country", log_x=True, size_max=60)
fig.show()Tree Maps
Treemap charts visualize hierarchical data using nested rectangles.
import numpy as np
df = px.data.gapminder().query("year == 2007")
fig = px.treemap(df, path=[px.Constant("world"), 'continent', 'country'], values='pop',
color='lifeExp', hover_data=['iso_alpha'],
color_continuous_scale='RdBu',
color_continuous_midpoint=np.average(df['lifeExp'], weights=df['pop']))
fig.update_layout(margin = dict(t=50, l=25, r=25, b=25))
fig.show()Box Plots
A box plot is a statistical representation of the distribution of a variable through its quartiles. The ends of the box represent the lower and upper quartiles, while the median (second quartile) is marked by a line inside the box.
import plotly.express as px
df = px.data.tips()
df.head()| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
fig = px.box(df, x="time", y="total_bill")
fig.show()fig = px.box(df, x="day", y="total_bill", color="smoker")
fig.show()Use the keyword arguments facet_row (resp. facet_col) to create faceted subplots, where different rows (resp. columns) correspond to different values of the dataframe column specified in facet_row.
fig = px.box(df, x="sex", y="total_bill", color="smoker",
facet_row="time", facet_col="day",
category_orders={"day": ["Thur", "Fri", "Sat", "Sun"],
"time": ["Lunch", "Dinner"]})
fig.show()Histograms
In statistics, a histogram is representation of the distribution of numerical data, where the data are binned and the count for each bin is represented. More generally, in Plotly a histogram is an aggregated bar chart, with several possible aggregation functions (e.g. sum, average, count…) which can be used to visualize data on categorical and date axes as well as linear axes.
df = px.data.iris()
fig = px.histogram(df, x="sepal_length", color="species")
fig.show()With the marginal keyword, a marginal is drawn alongside the histogram, visualizing the distribution.
fig = px.histogram(df, x="sepal_length", color="species",marginal="rug")
fig.show()fig = px.histogram(df, x="sepal_length", color="species",marginal="box")
fig.show()Scatter Plot Matrix
ScatterPlot Matrices are really useful for Exploratory Data Analysis purposes.
df = px.data.iris()
fig = px.scatter_matrix(df,
dimensions=["sepal_length", "sepal_width", "petal_length", "petal_width"],
color="species")
fig.show()Parallel Coordinates
In a parallel coordinates plot with px.parallel_coordinates(), each row of the DataFrame is represented by a polyline mark which traverses a set of parallel axes, one for each of the dimensions.
fig = px.parallel_coordinates(df, color="species_id",
dimensions=['sepal_width', 'sepal_length', 'petal_width'
],
color_continuous_scale=px.colors.diverging.Tealrose,
color_continuous_midpoint=2,width=600, height=200)
fig.show()fig = px.parallel_categories(df,color="species_id")
fig.show()Violin Plot
A violin plot is a statistical representation of numerical data. It is similar to a box plot, with the addition of a rotated kernel density plot on each side.
df = px.data.tips()
fig = px.violin(df, x="time", y="total_bill")
fig.show()fig = px.violin(df, x="day", y="total_bill", color="smoker")
fig.show()Use the keyword arguments facet_row (resp. facet_col) to create faceted subplots, where different rows (resp. columns) correspond to different values of the dataframe column specified in facet_row.
fig = px.violin(df, x="sex", y="total_bill", color="smoker",
facet_col="day",
category_orders={"day": [ "Fri", "Sat", "Sun"],
})
fig.show()Density Contour
A 2D histogram contour plot, also known as a density contour plot, is a 2-dimensional generalization of a histogram which resembles a contour plot but is computed by grouping a set of points specified by their x and y coordinates into bins, and applying an aggregation function such as count or sum (if z is provided) to compute the value to be used to compute contours.
df = px.data.tips()
fig = px.density_contour(df, x="total_bill", y="tip")
fig.show()Marginal plots can be added to visualize the 1-dimensional distributions of the two variables. Here we use a marginal histogram. Other allowable values are violin, box and rug.
df = px.data.tips()
fig = px.density_contour(df, x="total_bill", y="tip", marginal_x="histogram", marginal_y="histogram")
fig.show()Plotly Express density contours can be continuously-colored and labeled:
df = px.data.tips()
fig = px.density_contour(df, x="total_bill", y="tip")
fig.update_traces(contours_coloring="fill", contours_showlabels = True)
fig.show()20.3 Geolocated visualizations
Geolocated information is pivotal in data science because it provides spatial context, allowing analysts to understand how location influences behaviors, trends, and outcomes. This spatial context is particularly valuable for understanding phenomena like consumer behavior, disease spread, or crime patterns. For instance, customer buying patterns can vary significantly depending on geographic factors such as climate, local economy, and culture. By layering geolocation onto traditional data, analysts can uncover insights that are location-specific, which would be missed if only considering non-spatial data points. This added depth helps in accurately diagnosing and predicting outcomes across sectors.
Geospatial data also enhances the accuracy of predictive models by including location-specific factors that impact outcomes. In real estate, for example, models predicting property prices are more accurate when they incorporate geographic elements such as neighborhood features, proximity to services, and environmental risks. Likewise, in fields like predictive maintenance for infrastructure, geolocation can help identify areas where environmental conditions might accelerate wear and tear on assets like pipelines or power lines. Such insights enable industries to create more tailored and precise predictive models, resulting in better resource allocation and risk management.
Geolocation data is a critical tool in optimizing logistics and resource allocation across various sectors. In emergency response, for example, understanding the geographic distribution of disaster-affected areas allows responders to plan evacuations, distribute resources, and allocate medical services more effectively. Similarly, businesses in logistics use geolocation to plan efficient routes, saving time and reducing operational costs. Retailers also use spatial data to determine store locations based on factors like foot traffic and demographic distributions, ensuring they reach their target customers more effectively.
Plotly offers several methods to implement geolocated visualizations, refer to the following table for available methods:
| Map Type | Function/Module | Typical Use Cases |
|---|---|---|
| Tile Map (Scatter) | scatter_mapbox |
Visualizing geolocated data, urban and logistics planning |
| Tile Map (Choropleth) | choropleth_mapbox |
Demographic, economic, and election data |
| Density Map | density_mapbox |
Population density, event intensity, risk mapping |
| Scatter Geo Map | scatter_geo |
Climate data, world population, and regional comparisons |
| Choropleth Geo Map | choropleth / choropleth_geo |
Economic, public health, and global indicator analysis |
| Line Geo Map | line_geo |
Airline routes, migration paths, and trade routes |
| Bubble Map | scatter_mapbox or scatter_geo |
Economic activity, regional comparisons, and social data |
| Filled Area Map | choropleth_mapbox or custom shapes |
Zoning, area-based analysis, and regional segmentation |
| Hexbin Mapbox | hexbin_mapbox (custom) |
Geospatial clustering, density visualization |
Choropleth Maps
A Choropleth Map is a map composed of colored polygons. It is used to represent spatial variations of a quantity
Making choropleth maps requires two main types of input:
- Geometry information. This can either be a supplied GeoJSON file where each feature has either an id field or some identifying value in properties; or one of the built-in geometries within plotly, for instance US states or world countries.
- A list of values indexed by feature identifier.
The following code loads a GeoJSON file containing the geometry information for US counties, feature.id is a FIPS code, a five-digit Federal Information Processing Standards code which uniquely identifies counties and county equivalents in the United States,
from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
counties["features"][10]{'type': 'Feature',
'properties': {'GEO_ID': '0500000US01099',
'STATE': '01',
'COUNTY': '099',
'NAME': 'Monroe',
'LSAD': 'County',
'CENSUSAREA': 1025.675},
'geometry': {'type': 'Polygon',
'coordinates': [[[-86.905899, 31.753035],
[-87.052284, 31.716761],
[-87.135051, 31.642417],
[-87.166581, 31.519561],
[-87.427455, 31.260386],
[-87.61589, 31.244458],
[-87.765152, 31.297346],
[-87.784796, 31.324672],
[-87.665572, 31.423166],
[-87.603137, 31.409556],
[-87.565413, 31.553573],
[-87.566841, 31.697115],
[-87.516131, 31.697824],
[-87.50093, 31.829251],
[-86.906899, 31.830628],
[-86.905899, 31.753035]]]},
'id': '01099'}The following code loads unemployment data by county. The data is indexed by FIPS code.
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
df.head()| fips | unemp | |
|---|---|---|
| 0 | 01001 | 5.3 |
| 1 | 01003 | 5.4 |
| 2 | 01005 | 8.6 |
| 3 | 01007 | 6.6 |
| 4 | 01009 | 5.5 |
With the two previous datasets you can develop a choropleth map geolocating unemployment across the USA, as follows:
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()Bubble Maps
Bubble maps in Plotly are an effective way to display data points with varying sizes on a geographic map, where the size of each “bubble” represents a particular data value. For instance:
import plotly.express as px
df = px.data.gapminder().query("year==2007")
fig = px.scatter_geo(df, locations="iso_alpha", color="continent",
hover_name="country", size="pop"
)
fig.show()20.4 Dashboards
Dash waht is it ?
Hello World Dashboard
The following example illustrates a minimal ‘Hello World’ dashboard using dash. It simply produces a web page displaying the text “Hello World”
The following code:
- Initializes a new instance of the
Dash()application and assigns it to the variableapp. By creating an instance of Dash, we set up a web application with its own server. - Defines the layout of the
Dash()app, settingapp.layoutto an HTMLelement that will display the text “Hello World”. So when the app runs, it will render a single page displaying “Hello World.” - Then runs the
Dash()app, launching the server that hosts the app.
from dash import Dash, html
app = Dash()
app.layout = [html.Div(children='Hello World')]
app.run(debug=True)
Connecting the data
Indeed we want dashboards to display data-based visualization. The following code builds on the previous one this time incorporating an external datasource.
To do so, in addition to the app title, we add the dash_table.DataTable() method and read the pandas dataframe into the table.
# Import packages
from dash import Dash, html, dash_table
import pandas as pd
# Incorporate data
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminder2007.csv')
# Initialize the app
app = Dash()
# App layout
app.layout = [
html.Div(children='My First App with Data'),
dash_table.DataTable(data=df.to_dict('records'), page_size=10)
]
app.run(debug=True)
Visualizing the data
Dash applications can display Plotly based visualizations. The following example creates a boxplot associated with the data.
To do so we import the dcc module (DCC stands for Dash Core Components). This module includes a Graph method called dcc.Graph(), which is used to render interactive graphs. We also import the plotly.express library to build the interactive graphs.
# Import packages
from dash import Dash, html, dash_table, dcc
import pandas as pd
import plotly.express as px
# Incorporate data
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminder2007.csv')
# Initialize the app
app = Dash()
# App layout
app.layout = [
html.Div(children='My First App with Data and a Graph'),
dash_table.DataTable(data=df.to_dict('records'), page_size=5),
dcc.Graph(figure=px.box(df, x='continent', y='lifeExp'))
]
# Run the app
app.run(debug=True)
Controls and Callbacks
So far you have built a static app that displays tabular data and a graph. However, as you develop more sophisticated Dash apps, you will likely want to give the app user more freedom to interact with the app and explore the data in greater depth. To achieve that, you will need to add controls to the app by using the callback function.
The following example builds on the previous one by:
Adding a radio buttons method,
dcc.RadioItems(). There are three options, one for every radio button. The ‘lifeExp’ option is assigned to the value property, making it the currently selected value.Defining a callback that links the radio button selection to the graph, making the app interactive.
- A callback is a decorator used to define an interactive component. It defines:
Output(): Specifies that the figure property of the component with ID controls-and-graph (the graph) will be updated.Input(): Watches the value property of the component with ID controls-and-radio-item (the radio buttons).
- The function
def update_graph()takes the selected radio button value as col_chosen. The function:- Inside the function,
px.histogram()creates a histogram plot wherex='continent'groups the data by continent, andy=col_chosen(the selected value) shows the average value of the chosen metric (pop, lifeExp, or gdpPercap). histfunc='avg'calculates the average of the specified column for each continent.- Finally it returns the updated figure to be displayed in the graph component.
- Inside the function,
- A callback is a decorator used to define an interactive component. It defines:
# Import packages
from dash import Dash, html, dash_table, dcc, callback, Output, Input
import pandas as pd
import plotly.express as px
# Incorporate data
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminder2007.csv')
# Initialize the app
app = Dash()
# App layout
app.layout = [
html.Div(children='My First App with Data, Graph, and Controls'),
html.Hr(),
dcc.RadioItems(options=['pop', 'lifeExp', 'gdpPercap'], value='lifeExp', id='controls-and-radio-item'),
dash_table.DataTable(data=df.to_dict('records'), page_size=6),
dcc.Graph(figure={}, id='controls-and-graph')
]
# Add controls to build the interaction
@callback(
Output(component_id='controls-and-graph', component_property='figure'),
Input(component_id='controls-and-radio-item', component_property='value')
)
def update_graph(col_chosen):
fig = px.histogram(df, x='continent', y=col_chosen, histfunc='avg')
return fig
# Run the app
if __name__ == '__main__':
app.run(debug=True)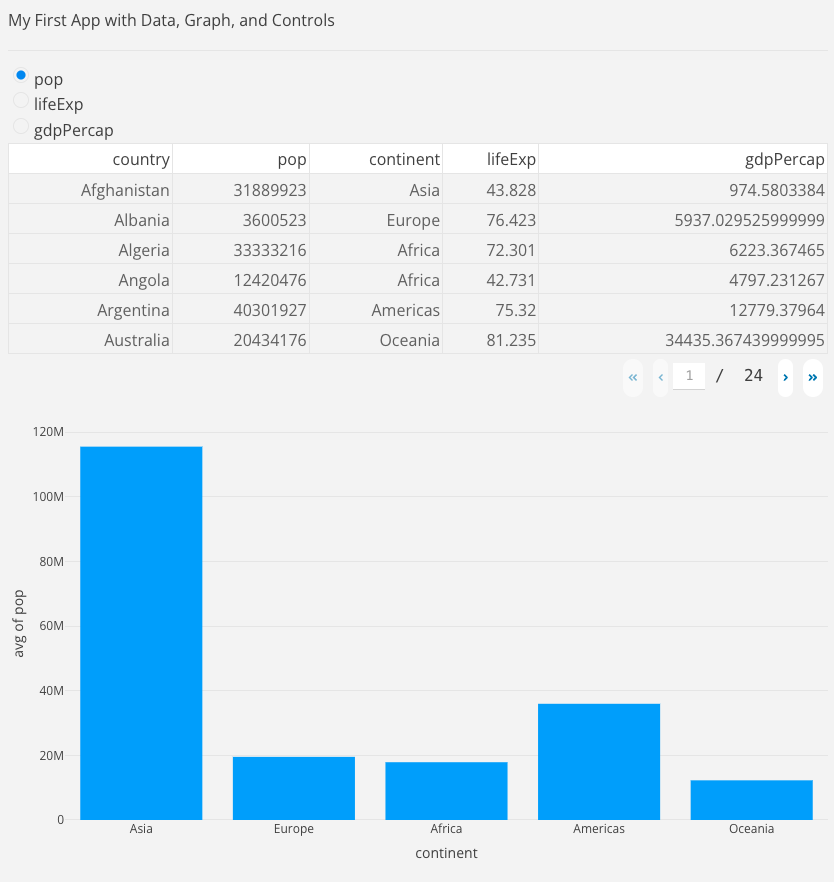
20.5 Advanced Visualization in Practice
First Example (Digital Marketing)
The following Jupyter Notebook illustrates how to develop advanced visualizations to support exploratory data analysis.
Second Example (Healthcare)
The following notebook Jupyter Notebook illustrates the use of advanced visualizations to provide insighs in healthcare contexts.
Third Example (Retail)
The following notebook Jupyter Notebook illustrates the use of advanced visualizations to provide insights in retail contexts
20.6 Conclusion
Advanced data visualization plays a pivotal role in modern data science by transforming complex datasets into actionable insights. Dashboards and interactive visualizations enable users to explore and analyze data in real-time, facilitating better decision-making and communication of findings. These tools consolidate diverse metrics into a single interface, allowing stakeholders to monitor performance, identify trends, and spot anomalies with ease. Geolocated data adds another dimension to this by revealing spatial patterns, such as customer behavior or regional sales performance, which are crucial for localized decision-making. Interactive visualizations enhance user engagement, enabling deep dives into data and fostering a clearer understanding of relationships and trends.
Incorporating advanced tools like Plotly enhances the creation of rich, interactive visualizations that go beyond static charts. Techniques such as scatter plots, heatmaps, and geospatial mapping empower analysts to convey intricate relationships and temporal changes effectively. By leveraging visual narratives, data scientists can communicate complex ideas more intuitively, making insights more accessible to diverse audiences. Advanced visualization not only supports exploratory data analysis but also plays a critical role in predictive modeling, operational optimization, and strategic planning. The ability to visualize data dynamically ensures that insights are not just impactful but also actionable, reinforcing their importance in the data science toolkit.
20.7 Further Readings
For those interested in additional examples and references on comprehensions feel free to check the following: